picohttpparse dependency
https://dev.eclipse.org/ipzilla/show_bug.cgi?id=23722 Also change to websockets compiled by default.pull/2438/head
parent
f4be3da2b7
commit
068c432b6c
@ -0,0 +1,116 @@
|
||||
PicoHTTPParser
|
||||
=============
|
||||
|
||||
Copyright (c) 2009-2014 [Kazuho Oku](https://github.com/kazuho), [Tokuhiro Matsuno](https://github.com/tokuhirom), [Daisuke Murase](https://github.com/typester), [Shigeo Mitsunari](https://github.com/herumi)
|
||||
|
||||
PicoHTTPParser is a tiny, primitive, fast HTTP request/response parser.
|
||||
|
||||
Unlike most parsers, it is stateless and does not allocate memory by itself.
|
||||
All it does is accept pointer to buffer and the output structure, and setups the pointers in the latter to point at the necessary portions of the buffer.
|
||||
|
||||
The code is widely deployed within Perl applications through popular modules that use it, including [Plack](https://metacpan.org/pod/Plack), [Starman](https://metacpan.org/pod/Starman), [Starlet](https://metacpan.org/pod/Starlet), [Furl](https://metacpan.org/pod/Furl). It is also the HTTP/1 parser of [H2O](https://github.com/h2o/h2o).
|
||||
|
||||
Check out [test.c] to find out how to use the parser.
|
||||
|
||||
The software is dual-licensed under the Perl License or the MIT License.
|
||||
|
||||
Usage
|
||||
-----
|
||||
|
||||
The library exposes four functions: `phr_parse_request`, `phr_parse_response`, `phr_parse_headers`, `phr_decode_chunked`.
|
||||
|
||||
### phr_parse_request
|
||||
|
||||
The example below reads an HTTP request from socket `sock` using `read(2)`, parses it using `phr_parse_request`, and prints the details.
|
||||
|
||||
```c
|
||||
char buf[4096], *method, *path;
|
||||
int pret, minor_version;
|
||||
struct phr_header headers[100];
|
||||
size_t buflen = 0, prevbuflen = 0, method_len, path_len, num_headers;
|
||||
ssize_t rret;
|
||||
|
||||
while (1) {
|
||||
/* read the request */
|
||||
while ((rret = read(sock, buf + buflen, sizeof(buf) - buflen)) == -1 && errno == EINTR)
|
||||
;
|
||||
if (rret <= 0)
|
||||
return IOError;
|
||||
prevbuflen = buflen;
|
||||
buflen += rret;
|
||||
/* parse the request */
|
||||
num_headers = sizeof(headers) / sizeof(headers[0]);
|
||||
pret = phr_parse_request(buf, buflen, &method, &method_len, &path, &path_len,
|
||||
&minor_version, headers, &num_headers, prevbuflen);
|
||||
if (pret > 0)
|
||||
break; /* successfully parsed the request */
|
||||
else if (pret == -1)
|
||||
return ParseError;
|
||||
/* request is incomplete, continue the loop */
|
||||
assert(pret == -2);
|
||||
if (buflen == sizeof(buf))
|
||||
return RequestIsTooLongError;
|
||||
}
|
||||
|
||||
printf("request is %d bytes long\n", pret);
|
||||
printf("method is %.*s\n", (int)method_len, method);
|
||||
printf("path is %.*s\n", (int)path_len, path);
|
||||
printf("HTTP version is 1.%d\n", minor_version);
|
||||
printf("headers:\n");
|
||||
for (i = 0; i != num_headers; ++i) {
|
||||
printf("%.*s: %.*s\n", (int)headers[i].name_len, headers[i].name,
|
||||
(int)headers[i].value_len, headers[i].value);
|
||||
}
|
||||
```
|
||||
|
||||
### phr_parse_response, phr_parse_headers
|
||||
|
||||
`phr_parse_response` and `phr_parse_headers` provide similar interfaces as `phr_parse_request`. `phr_parse_response` parses an HTTP response, and `phr_parse_headers` parses the headers only.
|
||||
|
||||
### phr_decode_chunked
|
||||
|
||||
The example below decodes incoming data in chunked-encoding. The data is decoded in-place.
|
||||
|
||||
```c
|
||||
struct phr_chunked_decoder decoder = {}; /* zero-clear */
|
||||
char *buf = malloc(4096);
|
||||
size_t size = 0, capacity = 4096, rsize;
|
||||
ssize_t rret, pret;
|
||||
|
||||
/* set consume_trailer to 1 to discard the trailing header, or the application
|
||||
* should call phr_parse_headers to parse the trailing header */
|
||||
decoder.consume_trailer = 1;
|
||||
|
||||
do {
|
||||
/* expand the buffer if necessary */
|
||||
if (size == capacity) {
|
||||
capacity *= 2;
|
||||
buf = realloc(buf, capacity);
|
||||
assert(buf != NULL);
|
||||
}
|
||||
/* read */
|
||||
while ((rret = read(sock, buf + size, capacity - size)) == -1 && errno == EINTR)
|
||||
;
|
||||
if (rret <= 0)
|
||||
return IOError;
|
||||
/* decode */
|
||||
rsize = rret;
|
||||
pret = phr_decode_chunked(&decoder, buf + size, &rsize);
|
||||
if (pret == -1)
|
||||
return ParseError;
|
||||
size += rsize;
|
||||
} while (pret == -2);
|
||||
|
||||
/* successfully decoded the chunked data */
|
||||
assert(pret >= 0);
|
||||
printf("decoded data is at %p (%zu bytes)\n", buf, size);
|
||||
```
|
||||
|
||||
Benchmark
|
||||
---------
|
||||
|
||||
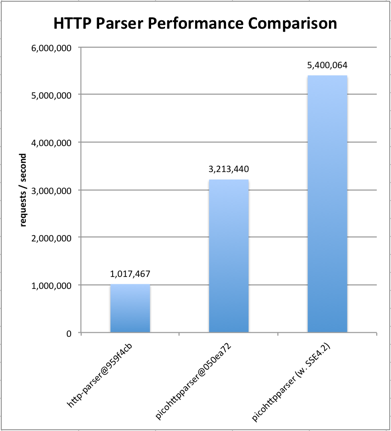
|
||||
|
||||
The benchmark code is from [fukamachi/fast-http@6b91103](https://github.com/fukamachi/fast-http/tree/6b9110347c7a3407310c08979aefd65078518478).
|
||||
|
||||
The internals of picohttpparser has been described to some extent in [my blog entry]( http://blog.kazuhooku.com/2014/11/the-internals-h2o-or-how-to-write-fast.html).
|
||||
@ -0,0 +1,665 @@
|
||||
/*
|
||||
* Copyright (c) 2009-2014 Kazuho Oku, Tokuhiro Matsuno, Daisuke Murase,
|
||||
* Shigeo Mitsunari
|
||||
*
|
||||
* The software is licensed under either the MIT License (below) or the Perl
|
||||
* license.
|
||||
*
|
||||
* Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
* of this software and associated documentation files (the "Software"), to
|
||||
* deal in the Software without restriction, including without limitation the
|
||||
* rights to use, copy, modify, merge, publish, distribute, sublicense, and/or
|
||||
* sell copies of the Software, and to permit persons to whom the Software is
|
||||
* furnished to do so, subject to the following conditions:
|
||||
*
|
||||
* The above copyright notice and this permission notice shall be included in
|
||||
* all copies or substantial portions of the Software.
|
||||
*
|
||||
* THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
* IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
* FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
* AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
* LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
|
||||
* FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS
|
||||
* IN THE SOFTWARE.
|
||||
*/
|
||||
|
||||
#include <assert.h>
|
||||
#include <stddef.h>
|
||||
#include <string.h>
|
||||
#ifdef __SSE4_2__
|
||||
#ifdef _MSC_VER
|
||||
#include <nmmintrin.h>
|
||||
#else
|
||||
#include <x86intrin.h>
|
||||
#endif
|
||||
#endif
|
||||
#include "picohttpparser.h"
|
||||
|
||||
#if __GNUC__ >= 3
|
||||
#define likely(x) __builtin_expect(!!(x), 1)
|
||||
#define unlikely(x) __builtin_expect(!!(x), 0)
|
||||
#else
|
||||
#define likely(x) (x)
|
||||
#define unlikely(x) (x)
|
||||
#endif
|
||||
|
||||
#ifdef _MSC_VER
|
||||
#define ALIGNED(n) _declspec(align(n))
|
||||
#else
|
||||
#define ALIGNED(n) __attribute__((aligned(n)))
|
||||
#endif
|
||||
|
||||
#define IS_PRINTABLE_ASCII(c) ((unsigned char)(c)-040u < 0137u)
|
||||
|
||||
#define CHECK_EOF() \
|
||||
if (buf == buf_end) { \
|
||||
*ret = -2; \
|
||||
return NULL; \
|
||||
}
|
||||
|
||||
#define EXPECT_CHAR_NO_CHECK(ch) \
|
||||
if (*buf++ != ch) { \
|
||||
*ret = -1; \
|
||||
return NULL; \
|
||||
}
|
||||
|
||||
#define EXPECT_CHAR(ch) \
|
||||
CHECK_EOF(); \
|
||||
EXPECT_CHAR_NO_CHECK(ch);
|
||||
|
||||
#define ADVANCE_TOKEN(tok, toklen) \
|
||||
do { \
|
||||
const char *tok_start = buf; \
|
||||
static const char ALIGNED(16) ranges2[16] = "\000\040\177\177"; \
|
||||
int found2; \
|
||||
buf = findchar_fast(buf, buf_end, ranges2, 4, &found2); \
|
||||
if (!found2) { \
|
||||
CHECK_EOF(); \
|
||||
} \
|
||||
while (1) { \
|
||||
if (*buf == ' ') { \
|
||||
break; \
|
||||
} else if (unlikely(!IS_PRINTABLE_ASCII(*buf))) { \
|
||||
if ((unsigned char)*buf < '\040' || *buf == '\177') { \
|
||||
*ret = -1; \
|
||||
return NULL; \
|
||||
} \
|
||||
} \
|
||||
++buf; \
|
||||
CHECK_EOF(); \
|
||||
} \
|
||||
tok = tok_start; \
|
||||
toklen = buf - tok_start; \
|
||||
} while (0)
|
||||
|
||||
static const char *token_char_map = "\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"
|
||||
"\0\1\0\1\1\1\1\1\0\0\1\1\0\1\1\0\1\1\1\1\1\1\1\1\1\1\0\0\0\0\0\0"
|
||||
"\0\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\0\0\0\1\1"
|
||||
"\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\0\1\0\1\0"
|
||||
"\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"
|
||||
"\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"
|
||||
"\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"
|
||||
"\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0";
|
||||
|
||||
static const char *findchar_fast(const char *buf, const char *buf_end, const char *ranges, size_t ranges_size, int *found)
|
||||
{
|
||||
*found = 0;
|
||||
#if __SSE4_2__
|
||||
if (likely(buf_end - buf >= 16)) {
|
||||
__m128i ranges16 = _mm_loadu_si128((const __m128i *)ranges);
|
||||
|
||||
size_t left = (buf_end - buf) & ~15;
|
||||
do {
|
||||
__m128i b16 = _mm_loadu_si128((const __m128i *)buf);
|
||||
int r = _mm_cmpestri(ranges16, ranges_size, b16, 16, _SIDD_LEAST_SIGNIFICANT | _SIDD_CMP_RANGES | _SIDD_UBYTE_OPS);
|
||||
if (unlikely(r != 16)) {
|
||||
buf += r;
|
||||
*found = 1;
|
||||
break;
|
||||
}
|
||||
buf += 16;
|
||||
left -= 16;
|
||||
} while (likely(left != 0));
|
||||
}
|
||||
#else
|
||||
/* suppress unused parameter warning */
|
||||
(void)buf_end;
|
||||
(void)ranges;
|
||||
(void)ranges_size;
|
||||
#endif
|
||||
return buf;
|
||||
}
|
||||
|
||||
static const char *get_token_to_eol(const char *buf, const char *buf_end, const char **token, size_t *token_len, int *ret)
|
||||
{
|
||||
const char *token_start = buf;
|
||||
|
||||
#ifdef __SSE4_2__
|
||||
static const char ALIGNED(16) ranges1[16] = "\0\010" /* allow HT */
|
||||
"\012\037" /* allow SP and up to but not including DEL */
|
||||
"\177\177"; /* allow chars w. MSB set */
|
||||
int found;
|
||||
buf = findchar_fast(buf, buf_end, ranges1, 6, &found);
|
||||
if (found)
|
||||
goto FOUND_CTL;
|
||||
#else
|
||||
/* find non-printable char within the next 8 bytes, this is the hottest code; manually inlined */
|
||||
while (likely(buf_end - buf >= 8)) {
|
||||
#define DOIT() \
|
||||
do { \
|
||||
if (unlikely(!IS_PRINTABLE_ASCII(*buf))) \
|
||||
goto NonPrintable; \
|
||||
++buf; \
|
||||
} while (0)
|
||||
DOIT();
|
||||
DOIT();
|
||||
DOIT();
|
||||
DOIT();
|
||||
DOIT();
|
||||
DOIT();
|
||||
DOIT();
|
||||
DOIT();
|
||||
#undef DOIT
|
||||
continue;
|
||||
NonPrintable:
|
||||
if ((likely((unsigned char)*buf < '\040') && likely(*buf != '\011')) || unlikely(*buf == '\177')) {
|
||||
goto FOUND_CTL;
|
||||
}
|
||||
++buf;
|
||||
}
|
||||
#endif
|
||||
for (;; ++buf) {
|
||||
CHECK_EOF();
|
||||
if (unlikely(!IS_PRINTABLE_ASCII(*buf))) {
|
||||
if ((likely((unsigned char)*buf < '\040') && likely(*buf != '\011')) || unlikely(*buf == '\177')) {
|
||||
goto FOUND_CTL;
|
||||
}
|
||||
}
|
||||
}
|
||||
FOUND_CTL:
|
||||
if (likely(*buf == '\015')) {
|
||||
++buf;
|
||||
EXPECT_CHAR('\012');
|
||||
*token_len = buf - 2 - token_start;
|
||||
} else if (*buf == '\012') {
|
||||
*token_len = buf - token_start;
|
||||
++buf;
|
||||
} else {
|
||||
*ret = -1;
|
||||
return NULL;
|
||||
}
|
||||
*token = token_start;
|
||||
|
||||
return buf;
|
||||
}
|
||||
|
||||
static const char *is_complete(const char *buf, const char *buf_end, size_t last_len, int *ret)
|
||||
{
|
||||
int ret_cnt = 0;
|
||||
buf = last_len < 3 ? buf : buf + last_len - 3;
|
||||
|
||||
while (1) {
|
||||
CHECK_EOF();
|
||||
if (*buf == '\015') {
|
||||
++buf;
|
||||
CHECK_EOF();
|
||||
EXPECT_CHAR('\012');
|
||||
++ret_cnt;
|
||||
} else if (*buf == '\012') {
|
||||
++buf;
|
||||
++ret_cnt;
|
||||
} else {
|
||||
++buf;
|
||||
ret_cnt = 0;
|
||||
}
|
||||
if (ret_cnt == 2) {
|
||||
return buf;
|
||||
}
|
||||
}
|
||||
|
||||
*ret = -2;
|
||||
return NULL;
|
||||
}
|
||||
|
||||
#define PARSE_INT(valp_, mul_) \
|
||||
if (*buf < '0' || '9' < *buf) { \
|
||||
buf++; \
|
||||
*ret = -1; \
|
||||
return NULL; \
|
||||
} \
|
||||
*(valp_) = (mul_) * (*buf++ - '0');
|
||||
|
||||
#define PARSE_INT_3(valp_) \
|
||||
do { \
|
||||
int res_ = 0; \
|
||||
PARSE_INT(&res_, 100) \
|
||||
*valp_ = res_; \
|
||||
PARSE_INT(&res_, 10) \
|
||||
*valp_ += res_; \
|
||||
PARSE_INT(&res_, 1) \
|
||||
*valp_ += res_; \
|
||||
} while (0)
|
||||
|
||||
/* returned pointer is always within [buf, buf_end), or null */
|
||||
static const char *parse_token(const char *buf, const char *buf_end, const char **token, size_t *token_len, char next_char,
|
||||
int *ret)
|
||||
{
|
||||
/* We use pcmpestri to detect non-token characters. This instruction can take no more than eight character ranges (8*2*8=128
|
||||
* bits that is the size of a SSE register). Due to this restriction, characters `|` and `~` are handled in the slow loop. */
|
||||
static const char ALIGNED(16) ranges[] = "\x00 " /* control chars and up to SP */
|
||||
"\"\"" /* 0x22 */
|
||||
"()" /* 0x28,0x29 */
|
||||
",," /* 0x2c */
|
||||
"//" /* 0x2f */
|
||||
":@" /* 0x3a-0x40 */
|
||||
"[]" /* 0x5b-0x5d */
|
||||
"{\xff"; /* 0x7b-0xff */
|
||||
const char *buf_start = buf;
|
||||
int found;
|
||||
buf = findchar_fast(buf, buf_end, ranges, sizeof(ranges) - 1, &found);
|
||||
if (!found) {
|
||||
CHECK_EOF();
|
||||
}
|
||||
while (1) {
|
||||
if (*buf == next_char) {
|
||||
break;
|
||||
} else if (!token_char_map[(unsigned char)*buf]) {
|
||||
*ret = -1;
|
||||
return NULL;
|
||||
}
|
||||
++buf;
|
||||
CHECK_EOF();
|
||||
}
|
||||
*token = buf_start;
|
||||
*token_len = buf - buf_start;
|
||||
return buf;
|
||||
}
|
||||
|
||||
/* returned pointer is always within [buf, buf_end), or null */
|
||||
static const char *parse_http_version(const char *buf, const char *buf_end, int *minor_version, int *ret)
|
||||
{
|
||||
/* we want at least [HTTP/1.<two chars>] to try to parse */
|
||||
if (buf_end - buf < 9) {
|
||||
*ret = -2;
|
||||
return NULL;
|
||||
}
|
||||
EXPECT_CHAR_NO_CHECK('H');
|
||||
EXPECT_CHAR_NO_CHECK('T');
|
||||
EXPECT_CHAR_NO_CHECK('T');
|
||||
EXPECT_CHAR_NO_CHECK('P');
|
||||
EXPECT_CHAR_NO_CHECK('/');
|
||||
EXPECT_CHAR_NO_CHECK('1');
|
||||
EXPECT_CHAR_NO_CHECK('.');
|
||||
PARSE_INT(minor_version, 1);
|
||||
return buf;
|
||||
}
|
||||
|
||||
static const char *parse_headers(const char *buf, const char *buf_end, struct phr_header *headers, size_t *num_headers,
|
||||
size_t max_headers, int *ret)
|
||||
{
|
||||
for (;; ++*num_headers) {
|
||||
CHECK_EOF();
|
||||
if (*buf == '\015') {
|
||||
++buf;
|
||||
EXPECT_CHAR('\012');
|
||||
break;
|
||||
} else if (*buf == '\012') {
|
||||
++buf;
|
||||
break;
|
||||
}
|
||||
if (*num_headers == max_headers) {
|
||||
*ret = -1;
|
||||
return NULL;
|
||||
}
|
||||
if (!(*num_headers != 0 && (*buf == ' ' || *buf == '\t'))) {
|
||||
/* parsing name, but do not discard SP before colon, see
|
||||
* http://www.mozilla.org/security/announce/2006/mfsa2006-33.html */
|
||||
if ((buf = parse_token(buf, buf_end, &headers[*num_headers].name, &headers[*num_headers].name_len, ':', ret)) == NULL) {
|
||||
return NULL;
|
||||
}
|
||||
if (headers[*num_headers].name_len == 0) {
|
||||
*ret = -1;
|
||||
return NULL;
|
||||
}
|
||||
++buf;
|
||||
for (;; ++buf) {
|
||||
CHECK_EOF();
|
||||
if (!(*buf == ' ' || *buf == '\t')) {
|
||||
break;
|
||||
}
|
||||
}
|
||||
} else {
|
||||
headers[*num_headers].name = NULL;
|
||||
headers[*num_headers].name_len = 0;
|
||||
}
|
||||
const char *value;
|
||||
size_t value_len;
|
||||
if ((buf = get_token_to_eol(buf, buf_end, &value, &value_len, ret)) == NULL) {
|
||||
return NULL;
|
||||
}
|
||||
/* remove trailing SPs and HTABs */
|
||||
const char *value_end = value + value_len;
|
||||
for (; value_end != value; --value_end) {
|
||||
const char c = *(value_end - 1);
|
||||
if (!(c == ' ' || c == '\t')) {
|
||||
break;
|
||||
}
|
||||
}
|
||||
headers[*num_headers].value = value;
|
||||
headers[*num_headers].value_len = value_end - value;
|
||||
}
|
||||
return buf;
|
||||
}
|
||||
|
||||
static const char *parse_request(const char *buf, const char *buf_end, const char **method, size_t *method_len, const char **path,
|
||||
size_t *path_len, int *minor_version, struct phr_header *headers, size_t *num_headers,
|
||||
size_t max_headers, int *ret)
|
||||
{
|
||||
/* skip first empty line (some clients add CRLF after POST content) */
|
||||
CHECK_EOF();
|
||||
if (*buf == '\015') {
|
||||
++buf;
|
||||
EXPECT_CHAR('\012');
|
||||
} else if (*buf == '\012') {
|
||||
++buf;
|
||||
}
|
||||
|
||||
/* parse request line */
|
||||
if ((buf = parse_token(buf, buf_end, method, method_len, ' ', ret)) == NULL) {
|
||||
return NULL;
|
||||
}
|
||||
do {
|
||||
++buf;
|
||||
CHECK_EOF();
|
||||
} while (*buf == ' ');
|
||||
ADVANCE_TOKEN(*path, *path_len);
|
||||
do {
|
||||
++buf;
|
||||
CHECK_EOF();
|
||||
} while (*buf == ' ');
|
||||
if (*method_len == 0 || *path_len == 0) {
|
||||
*ret = -1;
|
||||
return NULL;
|
||||
}
|
||||
if ((buf = parse_http_version(buf, buf_end, minor_version, ret)) == NULL) {
|
||||
return NULL;
|
||||
}
|
||||
if (*buf == '\015') {
|
||||
++buf;
|
||||
EXPECT_CHAR('\012');
|
||||
} else if (*buf == '\012') {
|
||||
++buf;
|
||||
} else {
|
||||
*ret = -1;
|
||||
return NULL;
|
||||
}
|
||||
|
||||
return parse_headers(buf, buf_end, headers, num_headers, max_headers, ret);
|
||||
}
|
||||
|
||||
int phr_parse_request(const char *buf_start, size_t len, const char **method, size_t *method_len, const char **path,
|
||||
size_t *path_len, int *minor_version, struct phr_header *headers, size_t *num_headers, size_t last_len)
|
||||
{
|
||||
const char *buf = buf_start, *buf_end = buf_start + len;
|
||||
size_t max_headers = *num_headers;
|
||||
int r;
|
||||
|
||||
*method = NULL;
|
||||
*method_len = 0;
|
||||
*path = NULL;
|
||||
*path_len = 0;
|
||||
*minor_version = -1;
|
||||
*num_headers = 0;
|
||||
|
||||
/* if last_len != 0, check if the request is complete (a fast countermeasure
|
||||
againt slowloris */
|
||||
if (last_len != 0 && is_complete(buf, buf_end, last_len, &r) == NULL) {
|
||||
return r;
|
||||
}
|
||||
|
||||
if ((buf = parse_request(buf, buf_end, method, method_len, path, path_len, minor_version, headers, num_headers, max_headers,
|
||||
&r)) == NULL) {
|
||||
return r;
|
||||
}
|
||||
|
||||
return (int)(buf - buf_start);
|
||||
}
|
||||
|
||||
static const char *parse_response(const char *buf, const char *buf_end, int *minor_version, int *status, const char **msg,
|
||||
size_t *msg_len, struct phr_header *headers, size_t *num_headers, size_t max_headers, int *ret)
|
||||
{
|
||||
/* parse "HTTP/1.x" */
|
||||
if ((buf = parse_http_version(buf, buf_end, minor_version, ret)) == NULL) {
|
||||
return NULL;
|
||||
}
|
||||
/* skip space */
|
||||
if (*buf != ' ') {
|
||||
*ret = -1;
|
||||
return NULL;
|
||||
}
|
||||
do {
|
||||
++buf;
|
||||
CHECK_EOF();
|
||||
} while (*buf == ' ');
|
||||
/* parse status code, we want at least [:digit:][:digit:][:digit:]<other char> to try to parse */
|
||||
if (buf_end - buf < 4) {
|
||||
*ret = -2;
|
||||
return NULL;
|
||||
}
|
||||
PARSE_INT_3(status);
|
||||
|
||||
/* get message including preceding space */
|
||||
if ((buf = get_token_to_eol(buf, buf_end, msg, msg_len, ret)) == NULL) {
|
||||
return NULL;
|
||||
}
|
||||
if (*msg_len == 0) {
|
||||
/* ok */
|
||||
} else if (**msg == ' ') {
|
||||
/* Remove preceding space. Successful return from `get_token_to_eol` guarantees that we would hit something other than SP
|
||||
* before running past the end of the given buffer. */
|
||||
do {
|
||||
++*msg;
|
||||
--*msg_len;
|
||||
} while (**msg == ' ');
|
||||
} else {
|
||||
/* garbage found after status code */
|
||||
*ret = -1;
|
||||
return NULL;
|
||||
}
|
||||
|
||||
return parse_headers(buf, buf_end, headers, num_headers, max_headers, ret);
|
||||
}
|
||||
|
||||
int phr_parse_response(const char *buf_start, size_t len, int *minor_version, int *status, const char **msg, size_t *msg_len,
|
||||
struct phr_header *headers, size_t *num_headers, size_t last_len)
|
||||
{
|
||||
const char *buf = buf_start, *buf_end = buf + len;
|
||||
size_t max_headers = *num_headers;
|
||||
int r;
|
||||
|
||||
*minor_version = -1;
|
||||
*status = 0;
|
||||
*msg = NULL;
|
||||
*msg_len = 0;
|
||||
*num_headers = 0;
|
||||
|
||||
/* if last_len != 0, check if the response is complete (a fast countermeasure
|
||||
against slowloris */
|
||||
if (last_len != 0 && is_complete(buf, buf_end, last_len, &r) == NULL) {
|
||||
return r;
|
||||
}
|
||||
|
||||
if ((buf = parse_response(buf, buf_end, minor_version, status, msg, msg_len, headers, num_headers, max_headers, &r)) == NULL) {
|
||||
return r;
|
||||
}
|
||||
|
||||
return (int)(buf - buf_start);
|
||||
}
|
||||
|
||||
int phr_parse_headers(const char *buf_start, size_t len, struct phr_header *headers, size_t *num_headers, size_t last_len)
|
||||
{
|
||||
const char *buf = buf_start, *buf_end = buf + len;
|
||||
size_t max_headers = *num_headers;
|
||||
int r;
|
||||
|
||||
*num_headers = 0;
|
||||
|
||||
/* if last_len != 0, check if the response is complete (a fast countermeasure
|
||||
against slowloris */
|
||||
if (last_len != 0 && is_complete(buf, buf_end, last_len, &r) == NULL) {
|
||||
return r;
|
||||
}
|
||||
|
||||
if ((buf = parse_headers(buf, buf_end, headers, num_headers, max_headers, &r)) == NULL) {
|
||||
return r;
|
||||
}
|
||||
|
||||
return (int)(buf - buf_start);
|
||||
}
|
||||
|
||||
enum {
|
||||
CHUNKED_IN_CHUNK_SIZE,
|
||||
CHUNKED_IN_CHUNK_EXT,
|
||||
CHUNKED_IN_CHUNK_DATA,
|
||||
CHUNKED_IN_CHUNK_CRLF,
|
||||
CHUNKED_IN_TRAILERS_LINE_HEAD,
|
||||
CHUNKED_IN_TRAILERS_LINE_MIDDLE
|
||||
};
|
||||
|
||||
static int decode_hex(int ch)
|
||||
{
|
||||
if ('0' <= ch && ch <= '9') {
|
||||
return ch - '0';
|
||||
} else if ('A' <= ch && ch <= 'F') {
|
||||
return ch - 'A' + 0xa;
|
||||
} else if ('a' <= ch && ch <= 'f') {
|
||||
return ch - 'a' + 0xa;
|
||||
} else {
|
||||
return -1;
|
||||
}
|
||||
}
|
||||
|
||||
ssize_t phr_decode_chunked(struct phr_chunked_decoder *decoder, char *buf, size_t *_bufsz)
|
||||
{
|
||||
size_t dst = 0, src = 0, bufsz = *_bufsz;
|
||||
ssize_t ret = -2; /* incomplete */
|
||||
|
||||
while (1) {
|
||||
switch (decoder->_state) {
|
||||
case CHUNKED_IN_CHUNK_SIZE:
|
||||
for (;; ++src) {
|
||||
int v;
|
||||
if (src == bufsz)
|
||||
goto Exit;
|
||||
if ((v = decode_hex(buf[src])) == -1) {
|
||||
if (decoder->_hex_count == 0) {
|
||||
ret = -1;
|
||||
goto Exit;
|
||||
}
|
||||
break;
|
||||
}
|
||||
if (decoder->_hex_count == sizeof(size_t) * 2) {
|
||||
ret = -1;
|
||||
goto Exit;
|
||||
}
|
||||
decoder->bytes_left_in_chunk = decoder->bytes_left_in_chunk * 16 + v;
|
||||
++decoder->_hex_count;
|
||||
}
|
||||
decoder->_hex_count = 0;
|
||||
decoder->_state = CHUNKED_IN_CHUNK_EXT;
|
||||
/* fallthru */
|
||||
case CHUNKED_IN_CHUNK_EXT:
|
||||
/* RFC 7230 A.2 "Line folding in chunk extensions is disallowed" */
|
||||
for (;; ++src) {
|
||||
if (src == bufsz)
|
||||
goto Exit;
|
||||
if (buf[src] == '\012')
|
||||
break;
|
||||
}
|
||||
++src;
|
||||
if (decoder->bytes_left_in_chunk == 0) {
|
||||
if (decoder->consume_trailer) {
|
||||
decoder->_state = CHUNKED_IN_TRAILERS_LINE_HEAD;
|
||||
break;
|
||||
} else {
|
||||
goto Complete;
|
||||
}
|
||||
}
|
||||
decoder->_state = CHUNKED_IN_CHUNK_DATA;
|
||||
/* fallthru */
|
||||
case CHUNKED_IN_CHUNK_DATA: {
|
||||
size_t avail = bufsz - src;
|
||||
if (avail < decoder->bytes_left_in_chunk) {
|
||||
if (dst != src)
|
||||
memmove(buf + dst, buf + src, avail);
|
||||
src += avail;
|
||||
dst += avail;
|
||||
decoder->bytes_left_in_chunk -= avail;
|
||||
goto Exit;
|
||||
}
|
||||
if (dst != src)
|
||||
memmove(buf + dst, buf + src, decoder->bytes_left_in_chunk);
|
||||
src += decoder->bytes_left_in_chunk;
|
||||
dst += decoder->bytes_left_in_chunk;
|
||||
decoder->bytes_left_in_chunk = 0;
|
||||
decoder->_state = CHUNKED_IN_CHUNK_CRLF;
|
||||
}
|
||||
/* fallthru */
|
||||
case CHUNKED_IN_CHUNK_CRLF:
|
||||
for (;; ++src) {
|
||||
if (src == bufsz)
|
||||
goto Exit;
|
||||
if (buf[src] != '\015')
|
||||
break;
|
||||
}
|
||||
if (buf[src] != '\012') {
|
||||
ret = -1;
|
||||
goto Exit;
|
||||
}
|
||||
++src;
|
||||
decoder->_state = CHUNKED_IN_CHUNK_SIZE;
|
||||
break;
|
||||
case CHUNKED_IN_TRAILERS_LINE_HEAD:
|
||||
for (;; ++src) {
|
||||
if (src == bufsz)
|
||||
goto Exit;
|
||||
if (buf[src] != '\015')
|
||||
break;
|
||||
}
|
||||
if (buf[src++] == '\012')
|
||||
goto Complete;
|
||||
decoder->_state = CHUNKED_IN_TRAILERS_LINE_MIDDLE;
|
||||
/* fallthru */
|
||||
case CHUNKED_IN_TRAILERS_LINE_MIDDLE:
|
||||
for (;; ++src) {
|
||||
if (src == bufsz)
|
||||
goto Exit;
|
||||
if (buf[src] == '\012')
|
||||
break;
|
||||
}
|
||||
++src;
|
||||
decoder->_state = CHUNKED_IN_TRAILERS_LINE_HEAD;
|
||||
break;
|
||||
default:
|
||||
assert(!"decoder is corrupt");
|
||||
}
|
||||
}
|
||||
|
||||
Complete:
|
||||
ret = bufsz - src;
|
||||
Exit:
|
||||
if (dst != src)
|
||||
memmove(buf + dst, buf + src, bufsz - src);
|
||||
*_bufsz = dst;
|
||||
return ret;
|
||||
}
|
||||
|
||||
int phr_decode_chunked_is_in_data(struct phr_chunked_decoder *decoder)
|
||||
{
|
||||
return decoder->_state == CHUNKED_IN_CHUNK_DATA;
|
||||
}
|
||||
|
||||
#undef CHECK_EOF
|
||||
#undef EXPECT_CHAR
|
||||
#undef ADVANCE_TOKEN
|
||||
@ -0,0 +1,87 @@
|
||||
/*
|
||||
* Copyright (c) 2009-2014 Kazuho Oku, Tokuhiro Matsuno, Daisuke Murase,
|
||||
* Shigeo Mitsunari
|
||||
*
|
||||
* The software is licensed under either the MIT License (below) or the Perl
|
||||
* license.
|
||||
*
|
||||
* Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
* of this software and associated documentation files (the "Software"), to
|
||||
* deal in the Software without restriction, including without limitation the
|
||||
* rights to use, copy, modify, merge, publish, distribute, sublicense, and/or
|
||||
* sell copies of the Software, and to permit persons to whom the Software is
|
||||
* furnished to do so, subject to the following conditions:
|
||||
*
|
||||
* The above copyright notice and this permission notice shall be included in
|
||||
* all copies or substantial portions of the Software.
|
||||
*
|
||||
* THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
* IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
* FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
* AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
* LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
|
||||
* FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS
|
||||
* IN THE SOFTWARE.
|
||||
*/
|
||||
|
||||
#ifndef picohttpparser_h
|
||||
#define picohttpparser_h
|
||||
|
||||
#include <sys/types.h>
|
||||
|
||||
#ifdef _MSC_VER
|
||||
#define ssize_t intptr_t
|
||||
#endif
|
||||
|
||||
#ifdef __cplusplus
|
||||
extern "C" {
|
||||
#endif
|
||||
|
||||
/* contains name and value of a header (name == NULL if is a continuing line
|
||||
* of a multiline header */
|
||||
struct phr_header {
|
||||
const char *name;
|
||||
size_t name_len;
|
||||
const char *value;
|
||||
size_t value_len;
|
||||
};
|
||||
|
||||
/* returns number of bytes consumed if successful, -2 if request is partial,
|
||||
* -1 if failed */
|
||||
int phr_parse_request(const char *buf, size_t len, const char **method, size_t *method_len, const char **path, size_t *path_len,
|
||||
int *minor_version, struct phr_header *headers, size_t *num_headers, size_t last_len);
|
||||
|
||||
/* ditto */
|
||||
int phr_parse_response(const char *_buf, size_t len, int *minor_version, int *status, const char **msg, size_t *msg_len,
|
||||
struct phr_header *headers, size_t *num_headers, size_t last_len);
|
||||
|
||||
/* ditto */
|
||||
int phr_parse_headers(const char *buf, size_t len, struct phr_header *headers, size_t *num_headers, size_t last_len);
|
||||
|
||||
/* should be zero-filled before start */
|
||||
struct phr_chunked_decoder {
|
||||
size_t bytes_left_in_chunk; /* number of bytes left in current chunk */
|
||||
char consume_trailer; /* if trailing headers should be consumed */
|
||||
char _hex_count;
|
||||
char _state;
|
||||
};
|
||||
|
||||
/* the function rewrites the buffer given as (buf, bufsz) removing the chunked-
|
||||
* encoding headers. When the function returns without an error, bufsz is
|
||||
* updated to the length of the decoded data available. Applications should
|
||||
* repeatedly call the function while it returns -2 (incomplete) every time
|
||||
* supplying newly arrived data. If the end of the chunked-encoded data is
|
||||
* found, the function returns a non-negative number indicating the number of
|
||||
* octets left undecoded, that starts from the offset returned by `*bufsz`.
|
||||
* Returns -1 on error.
|
||||
*/
|
||||
ssize_t phr_decode_chunked(struct phr_chunked_decoder *decoder, char *buf, size_t *bufsz);
|
||||
|
||||
/* returns if the chunked decoder is in middle of chunked data */
|
||||
int phr_decode_chunked_is_in_data(struct phr_chunked_decoder *decoder);
|
||||
|
||||
#ifdef __cplusplus
|
||||
}
|
||||
#endif
|
||||
|
||||
#endif
|
||||
Loading…
Reference in New Issue