84 KiB
Chapter 4: Namespaces
4.1: Namespaces
Imagine a math teacher who wants to develop an interactive math program. For this program functions like cos, sin, tan etc. are to be used accepting arguments in degrees rather than arguments in radians. Unfortunately, the function name cos is already in use, and that function accepts radians as its arguments, rather than degrees.
Problems like these are usually solved by defining another name, e.g., the function name cosDegrees is defined. C++ offers an alternative solution through namespaces. Namespaces can be considered as areas or regions in the code in which identifiers may be defined. Identifiers defined in a namespace normally won't conflict with names already defined elsewhere (i.e., outside of their namespaces). So, a function cos (expecting angles in degrees) could be defined in a namespace Degrees. When calling cos from within Degrees you would call the cos function expecting degrees, rather than the standard cos function expecting radians.
4.1.1: Defining namespaces
Namespaces are defined according to the following syntax:
namespace identifier
{
// declared or defined entities
// (declarative region)
}
The identifier used when defining a namespace is a standard C++ identifier.
Within the declarative region, introduced in the above code example, functions, variables, structs, classes and even (nested) namespaces can be defined or declared. Namespaces cannot be defined within a function body. However, it is possible to define a namespace using multiple namespace declarations. Namespaces are open meaning that a namespace CppAnnotations could be defined in a file file1.cc and also in a file file2.cc. Entities defined in the CppAnnotations namespace of files file1.cc and file2.cc are then united in one CppAnnotations namespace region. For example:
// in file1.cc
namespace CppAnnotations
{
double cos(double argInDegrees)
{
...
}
}
// in file2.cc
namespace CppAnnotations
{
double sin(double argInDegrees)
{
...
}
}
Both sin and cos are now defined in the same CppAnnotations namespace.
Namespace entities can be defined outside of their namespaces. This topic is discussed in section [4.1.4.1]({{< relref "/docs/Name Spaces#4141-defining-entities-outside-of-their-namespaces" >}}).
4.1.1.1: Declaring entities in namespaces
Instead of defining entities in a namespace, entities may also be declared in a namespace. This allows us to put all the declarations in a header file that can thereupon be included in sources using the entities defined in the namespace. Such a header file could contain, e.g.,
namespace CppAnnotations
{
double cos(double degrees);
double sin(double degrees);
}
4.1.1.2: A closed namespace
Namespaces can be defined without a name. Such an anonymous namespace restricts the visibility of the defined entities to the source file defining the anonymous namespace.
Entities defined in the anonymous namespace are comparable to C's static functions and variables. In C++ the static keyword can still be used, but its preferred use is in class definitions (see chapter 7). In situations where in C `static variables or functions would have been used the anonymous namespace should be used in C++.
The anonymous namespace is a closed namespace: it is not possible to add entities to the same anonymous namespace using different source files.
4.1.2: Referring to entities
Given a namespace and its entities, the scope resolution operator can be used to refer to its entities. For example, the function cos() defined in the CppAnnotations namespace may be used as follows:
// assume CppAnnotations namespace is declared in the
// following header file:
#include <cppannotations>
int main()
{
cout << "The cosine of 60 degrees is: " <<
CppAnnotations::cos(60) << '\n';
}
This is a rather cumbersome way to refer to the cos() function in the CppAnnotations namespace, especially so if the function is frequently used. In cases like these an abbreviated form can be used after specifying a using declaration. Following
using CppAnnotations::cos; // note: no function prototype,
// just the name of the entity
// is required.
calling cos results in a call of the cos function defined in the CppAnnotations namespace. This implies that the standard cos function, accepting radians, is not automatically called anymore. To call that latter cos function the plain scope resolution operator should be used:
int main()
{
using CppAnnotations::cos;
...
cout << cos(60) // calls CppAnnotations::cos()
<< ::cos(1.5) // call the standard cos() function
<< '\n';
}
A using declaration can have restricted scope. It can be used inside a block. The using declaration prevents the definition of entities having the same name as the one used in the using declaration. It is not possible to specify a using declaration for a variable value in some namespace, and to define (or declare) an identically named object in a block also containing a using declaration. Example:
int main()
{
using CppAnnotations::value;
...
cout << value << '\n'; // uses CppAnnotations::value
int value; // error: value already declared.
}
4.1.2.1: The using directive
A generalized alternative to the using declaration is the using directive:
using namespace CppAnnotations;
Following this directive, all entities defined in the CppAnnotations namespace are used as if they were declared by using declarations.
While the using directive is a quick way to import all the names of a namespace (assuming the namespace has previously been declared or defined), it is at the same time a somewhat dirty way to do so, as it is less clear what entity is actually used in a particular block of code.
If, e.g., cos is defined in the CppAnnotations namespace, CppAnnotations::cos is going to be used when cos is called. However, if cos is not defined in the CppAnnotations namespace, the standard cos function will be used. The using directive does not document as clearly as the using declaration what entity will actually be used. Therefore use caution when applying the using directive.
Namespace declarations are context sensitive: when a using namespace declaration is specified inside a compound statement then the declaration is valid until the compound statement's closing curly bracket has been encountered. In the next example a string first is defined without explicit specifying std::string, but once the compound statement has ended the scope of the using namespace std declaration has also ended, and so std:: is required once again when defining second:
#include <string>
int main()
{
{
using namespace std;
string first;
}
std::string second;
}
A using namespace directive cannot be used within the declaration block of a class- or enumeration-type. E.g., the following example won't compile:
struct Namespace
{
using namespace std; // won't compile
};
4.1.2.2: Koenig lookup
If Koenig lookup were called the Koenig principle, it could have been the title of a new Ludlum novel. However, it is not. Instead it refers to a C++ technicality.
Koenig lookup refers to the fact that if a function is called without specifying its namespace, then the namespaces of its argument types are used to determine the function's namespace. If the namespace in which the argument types are defined contains such a function, then that function is used. This procedure is called the Koenig lookup.
As an illustration consider the next example. The function FBB::fun(FBB::Value v) is defined in the FBB namespace. It can be called without explicitly mentioning its namespace:
#include <iostream>
namespace FBB
{
enum Value // defines FBB::Value
{
FIRST
};
void fun(Value x)
{
std::cout << "fun called for " << x << '\n';
}
}
int main()
{
fun(FBB::FIRST); // Koenig lookup: no namespace
// for fun() specified
}
/*
generated output:
fun called for 0
*/
The compiler is rather smart when handling namespaces. If Value in the namespace FBB would have been defined as using Value = int then FBB::Value would be recognized as int, thus causing the Koenig lookup to fail.
As another example, consider the next program. Here two namespaces are involved, each defining their own fun function. There is no ambiguity, since the argument defines the namespace and FBB::fun is called:
#include <iostream>
namespace FBB
{
enum Value // defines FBB::Value
{
FIRST
};
void fun(Value x)
{
std::cout << "FBB::fun() called for " << x << '\n';
}
}
namespace ES
{
void fun(FBB::Value x)
{
std::cout << "ES::fun() called for " << x << '\n';
}
}
int main()
{
fun(FBB::FIRST); // No ambiguity: argument determines
// the namespace
}
/*
generated output:
FBB::fun() called for 0
*/
Here is an example in which there is an ambiguity: fun has two arguments, one from each namespace. The ambiguity must be resolved by the programmer:
#include <iostream>
namespace ES
{
enum Value // defines ES::Value
{
FIRST
};
}
namespace FBB
{
enum Value // defines FBB::Value
{
FIRST
};
void fun(Value x, ES::Value y)
{
std::cout << "FBB::fun() called\n";
}
}
namespace ES
{
void fun(FBB::Value x, Value y)
{
std::cout << "ES::fun() called\n";
}
}
int main()
{
// fun(FBB::FIRST, ES::FIRST); ambiguity: resolved by
// explicitly mentioning
// the namespace
ES::fun(FBB::FIRST, ES::FIRST);
}
/*
generated output:
ES::fun() called
*/
An interesting subtlety with namespaces is that definitions in one namespace may break the code defined in another namespace. It shows that namespaces may affect each other and that namespaces may backfire if we're not aware of their peculiarities. Consider the following example:
namespace FBB
{
struct Value
{};
void fun(int x);
void gun(Value x);
}
namespace ES
{
void fun(int x)
{
fun(x);
}
void gun(FBB::Value x)
{
gun(x);
}
}
Whatever happens, the programmer'd better not use any of the functions defined in the ES namespace, since that would result in infinite recursion. However, that's not the point. The point is that the programmer won't even be given the opportunity to call ES::fun since the compilation fails.
Compilation fails for gun but not for fun. But why is that so? Why is ES::fun flawlessly compiling while ES::gun isn't? In ES::fun fun(x) is called. As x's type is not defined in a namespace the Koenig lookup does not apply and fun calls itself with infinite recursion.
With ES::gun the argument is defined in the FBB namespace. Consequently, the FBB::gun function is a possible candidate to be called. But ES::gun itself also is possible as ES::gun's prototype perfectly matches the call gun(x).
Now consider the situation where FBB::gun has not yet been declared. Then there is of course no ambiguity. The programmer responsible for the ES namespace is resting happily. Some time after that the programmer who's maintaining the FBB namespace decides it may be nice to add a function gun(Value x) to the FBB namespace. Now suddenly the code in the namespace ES breaks because of an addition in a completely other namespace (FBB). Namespaces clearly are not completely independent of each other and we should be aware of subtleties like the above. Later in the C++ Annotations (chapter 11) we'll return to this issue.
Koenig lookup is only used in the context of namespaces. If a function is defined outside of a namespace, defining a parameter of a type that's defined inside a namespace, and that namespace also defines a function with an identical signature, then the compiler reports an ambiguity when that function is called. Here is an example, assuming the abovementioned namespace FBB is also available:
void gun(FBB::Value x);
int main(int argc, char **argv)
{
gun(FBB::Value{}); // ambiguity: FBB::gun and ::gun can both
// be called.
}
4.1.3: The standard namespace
The std namespace is reserved by C++. The standard defines many entities that are part of the runtime available software (e.g., cout, cin, cerr); the templates defined in the Standard Template Library (cf. chapter 18); and the Generic Algorithms (cf. chapter 19) are defined in the std namespace.
Regarding the discussion in the previous section, using declarations may be used when referring to entities in the std namespace. For example, to use the std::cout stream, the code may declare this object as follows:
#include <iostream>
using std::cout;
Often, however, the identifiers defined in the std namespace can all be accepted without much thought. Because of that, one frequently encounters a using directive, allowing the programmer to omit a namespace prefix when referring to any of the entities defined in the namespace specified with the using directive. Instead of specifying using declarations the following using directive is frequently encountered: construction like
#include <iostream>
using namespace std;
Should a using directive, rather than using declarations be used? As a rule of thumb one might decide to stick to using declarations, up to the point where the list becomes impractically long, at which point a using directive could be considered.
Two restrictions apply to using directives and declarations:
- Programmers should not declare or define anything inside the namespace
std. This is not compiler enforced but is imposed upon user code by the standard; - Using declarations and directives should not be imposed upon code written by third parties. In practice this means that using directives and declarations should be banned from header files and should only be used in source files (cf. section 7.11.1).
4.1.4: Nesting namespaces and namespace aliasing
Namespaces can be nested. Here is an example:
namespace CppAnnotations
{
int value;
namespace Virtual
{
void *pointer;
}
}
The variable value is defined in the CppAnnotations namespace. Within the CppAnnotations namespace another namespace (Virtual) is nested. Within that latter namespace the variable pointer is defined. To refer to these variable the following options are available:
-
The fully qualified names can be used. A fully qualified name of an entity is a list of all the namespaces that are encountered until reaching the definition of the entity. The namespaces and entity are glued together by the scope resolution operator:
int main() { CppAnnotations::value = 0; CppAnnotations::Virtual::pointer = 0; } -
A
using namespace CppAnnotationsdirective can be provided. Now value can be used without any prefix, butpointermust be used with theVirtual::prefix:using namespace CppAnnotations; int main() { value = 0; Virtual::pointer = 0; } -
A using namespace directive for the full namespace chain can be used. Now value needs its
CppAnnotationsprefix again, butpointerdoesn't require a prefix anymore:using namespace CppAnnotations::Virtual; int main() { CppAnnotations::value = 0; pointer = 0; } -
When using two separate using namespace directives none of the namespace prefixes are required anymore:
using namespace CppAnnotations; using namespace Virtual; int main() { value = 0; pointer = 0; } -
The same can be accomplished (i.e., no namespace prefixes) for specific variables by providing specific using declarations:
using CppAnnotations::value; using CppAnnotations::Virtual::pointer; int main() { value = 0; pointer = 0; } -
A combination of using namespace directives and using declarations can also be used. E.g., a using namespace directive can be used for the
CppAnnotations::Virtualnamespace, and a using declaration can be used for theCppAnnotations::valuevariable:using namespace CppAnnotations::Virtual; using CppAnnotations::value; int main() { value = 0; pointer = 0; }
Following a using namespace directive all entities of that namespace can be used without any further prefix. If a single using namespace directive is used to refer to a nested namespace, then all entities of that nested namespace can be used without any further prefix. However, the entities defined in the more shallow namespace(s) still need the shallow namespace's name(s). Only after providing specific using namespace directives or using declarations namespace qualifications can be omitted.
When fully qualified names are preferred but a long name like
CppAnnotations::Virtual::pointer
is considered too long, a namespace alias may be used:
namespace CV = CppAnnotations::Virtual;
This defines CV as an alias for the full name. The variable pointer may now be accessed using:
CV::pointer = 0;
A namespace alias can also be used in a using namespace directive or using declaration:
namespace CV = CppAnnotations::Virtual;
using namespace CV;
Nested namespace definitions
Starting with the C++17 standard, when nesting namespaces a nested namespace can directly be referred to using scope resolution operators. E.g.,
namespace Outer::Middle::Inner
{
// entities defined/declared here are defined/declared in the Inner
// namespace, which is defined in the Middle namespace, which is
// defined in the Outer namespace
}
4.1.4.1: Defining entities outside of their namespaces
It is not strictly necessary to define members of namespaces inside a namespace region. But before an entity is defined outside of a namespace it must have been declared inside its namespace.
To define an entity outside of its namespace its name must be fully qualified by prefixing the member by its namespaces. The definition may be provided at the global level or at intermediate levels in the case of nested namespaces. This allows us to define an entity belonging to namespace A::B within the region of namespace A.
Assume the type int INT8[8] is defined in the CppAnnotations::Virtual namespace. Furthermore assume that it is our intent to define a function squares, inside the namespace CppAnnotations::Virtual returning a pointer to CppAnnotations::Virtual::INT8.
Having defined the prerequisites within the CppAnnotations::Virtual namespace, our function could be defined as follows (cf. chapter 9 for coverage of the memory allocation operator new[]):
namespace CppAnnotations
{
namespace Virtual
{
void *pointer;
using INT8 = int[8];
INT8 *squares()
{
INT8 *ip = new INT8[1];
for (size_t idx = 0; idx != sizeof(INT8) / sizeof(int); ++idx)
(*ip)[idx] = (idx + 1) * (idx + 1);
return ip;
}
}
}
The function squares defines an array of one INT8 vector, and returns its address after initializing the vector by the squares of the first eight natural numbers.
Now the function squares can be defined outside of the CppAnnotations::Virtual namespace:
namespace CppAnnotations
{
namespace Virtual
{
void *pointer;
using INT8 = int[8];
INT8 *squares();
}
}
CppAnnotations::Virtual::INT8 *CppAnnotations::Virtual::squares()
{
INT8 *ip = new INT8[1];
for (size_t idx = 0; idx != sizeof(INT8) / sizeof(int); ++idx)
(*ip)[idx] = (idx + 1) * (idx + 1);
return ip;
}
In the above code fragment note the following:
squaresis declared inside of theCppAnnotations::Virtualnamespace.- The definition outside of the namespace region requires us to use the fully qualified name of the function and of its return type.
- Inside the body of the function squares we are within the
CppAnnotations::Virtualnamespace, so inside the function fully qualified names (e.g., forINT8) are not required any more.
Finally, note that the function could also have been defined in the CppAnnotations region. In that case the Virtual namespace would have been required when defining squares() and when specifying its return type, while the internals of the function would remain the same:
namespace CppAnnotations
{
namespace Virtual
{
void *pointer;
using INT8 = int[8];
INT8 *squares();
}
Virtual::INT8 *Virtual::squares()
{
INT8 *ip = new INT8[1];
for (size_t idx = 0; idx != sizeof(INT8) / sizeof(int); ++idx)
(*ip)[idx] = (idx + 1) * (idx + 1);
return ip;
}
}
4.2: The std::chrono namespace (handling time)
The C programming language offers tools like sleep(3) and select(2) to suspend program execution for a certain amount of time. And of course the family of time(3) functions for setting and displaying time
Sleep and select can be used for waiting, but as they were designed in an era when multi threading was unavailable, their usefulness is limited when used in multi threaded programs. Multi threading has become part of C++ (covered in detail in chapter 20), and additional time-related functions are available in the std::filesystem namespace, covered below in this chapter.
In multi threaded programs threads are frequently suspended, albeit usually for a very short time. E.g., when a thread wants to access a variable, but the variable is currently being updated by another thread, then the former thread should wait until the latter thread has completed the update. Updating a variable usually doesn't take much time, but if it takes an unexpectedly long time, then the former thread may want to be informed about that, so it can do something else while the latter thread is busy updating the variable. Interactions between threads like these cannot be realized with functions like sleep and select.
The std::chrono namespace bridges the gap between the traditionally available time-related functions and the time-related requirements of multi-threading and of the std::filesystem name space. All but the specific std::filesystem related time functionality is available after including the <chrono> header file. After including the <filesystem> header file the facilities of the std::filesystem are available.
Time can be measured in various resolutions: in Olympic games time differences of hundreds of seconds may make the distinction between a gold and silver medal, but when planning a vacation we might talk about months before we go on vacation. Time resolutions are specified through objects of the class std::ratio, which (apart from including the <chrono> header file) is also available after including the <ratio> header file.
Different events usually last for different amounts of time (given a specific time resolution). Amounts of time are specified through objects of the class std::chrono::duration.
Events can also be characterized by their points in time: midnight, January 1, 1970 GMT is a point in time, as is 19:00, December 5, 2010. Points in time are specified through objects of the class std::chrono::time_point.
It's not just that resolutions, durations of events, and points in time of events may differ, but the devices (clocks) we use for specifying time also differ. In the old days hour glasses were used (and sometimes they're still used when boiling eggs), but on the other hand we may use atomic clocks when measurements should be very precise. Four different types of clocks are available. The commonly used clock is std::chrono::system_clock, but in the context of the file system there's also an (implicitly defined) filesystem::__file_clock.
In the upcoming sections the details of the std::chrono namespace are covered. First we look at characteristics of time resolutions. How to handle amounts of time given their resolutions is covered next. The next section describes facilities for defining and handling time-points. The relationships between these types and the various clock-types are covered thereafter.
In this chapter the specification std::chrono:: is often omitted (in practice using namespace std followed by using namespace chrono is commonly used; [std::]chrono:: specifications are occasionally used to avoid ambiguities). Also, every now and then you'll encounter forward references to later chapters, like the reference to the chapter about multi-threading. These are hard to avoid, but studying those chapters at this point fortunately can be postponed without loss of continuity.
4.2.1: Time resolutions: std::ratio
Time resolutions (or units of time) are essential components of time specifications. Time resolutions are defined through objects of the class std::ratio.
Before the class ratio can be used, the <ratio> header file must be included. Instead the <chrono> header file can be included.
The class ratio requires two template arguments. These are positive integral numbers surrounded by pointed brackets defining, respectively, the numerator and denominator of a fraction (by default the denominator equals 1). Examples:
ratio<1> - representing one;
ratio<60> - representing 60
ratio<1, 1000> - representing 1/1000.
The class ratio defines two directly accessible static data members: num represents its numerator, den its denominator. A ratio definition by itself simply defines a certain amount. E.g., when executing the following program
#include <ratio>
#include <iostream>
using namespace std;
int main()
{
cout << ratio<5, 1000>::num << ',' << ratio<5, 1000>::den << '\n' <<
milli::num << ',' << milli::den << '\n';
}
the text 1,200 is displayed, as that's the amount represented by ratio<5, 1000>: ratio simplifies the fraction whenever possible.
A fairly large number of predefined ratio types exist. They are, like ratio itself, defined in the standard namespace and can be used instead of the more cumbersome ratio<x> or ratio<x, y> specification:
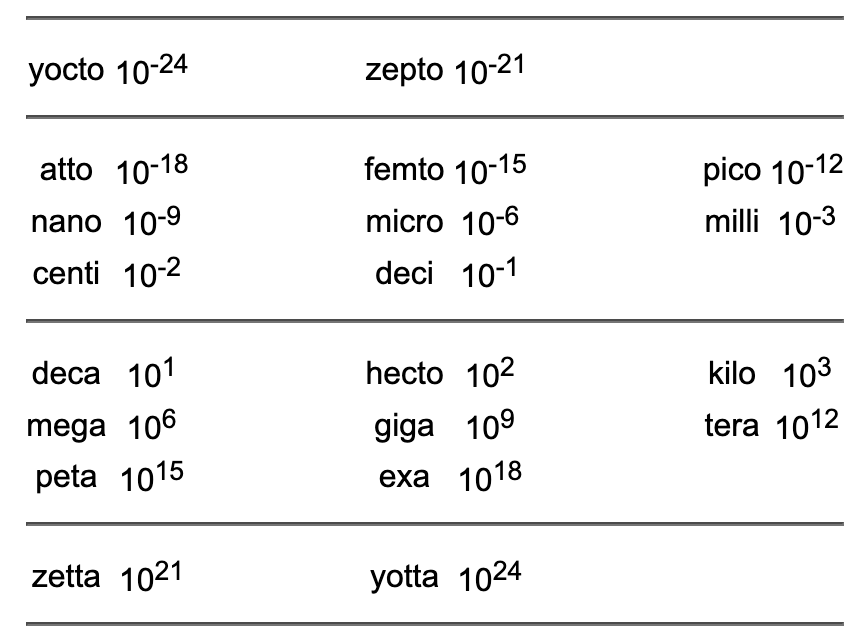
(note: the definitions of the types yocto, zepto, zetta and yotta use integral constants exceeding 64 bits. Although these constants are defined in C++, they are not available on 64 bit or smaller architectures.)
Time related ratios can very well be interpreted as fractions or multiple of seconds, with ratio<1, 1>z representing a resolution of one second.
Here is an example showing how these abbreviations can be used:
cout << milli::num << ',' << milli::den << '\n' <<
kilo::num << ',' << kilo::den << '\n';
4.2.2: Amounts of time: std::chrono::duration
Amounts of time are specified through objects of the class std::chrono::duration.
Before using the class duration the <chrono> header file must be included.
Like ratio the class duration requires two template arguments. A numeric type (int64_t is normally used) defining the type holding the duration's amount of time, and a time-resolution (called its resolution), usually specified through a std::ratio-type (often using one of its chrono abbreviations).
Using the predefined std::deca ratio, representing units of 10 seconds an interval of 30 minutes is defined as follows:
duration<int64_t, std::deca> halfHr(180);
Here halfHr represents a time interval of 180 deca-seconds, so 1800 seconds. Comparable to the predefined ratios predefined duration types are available:

Using these types, a time amount of 30 minutes can now simply be defined as minutes halfHour(30).
The two types that were specified when defining a duration<Type, Resolution> can be retrieved as, respectively,
-
rep, which is equivalent to the numeric type (like
int64_t). E.g.,seconds::repis equivalent toint64_t; -
period, which is equivalent to the ratio type (like
kilo) and soduration<int, kilo>::period::numis equal to 1000.
Duration objects can be constructed by specifying an argument of its numeric type:
- duration(Type const &value):
a specific duration of
valuetime units.Typerefers to the duration's numeric type (e.g.,int64_t). So, when defining
the argument 30 is stored inside itsminutes halfHour(30);int64_tdata member.
Duration supports copy- and move-constructors (cf. chapter 9) and its default constructor initializes its int64_t data member to zero.
The amount of time stored in a duration object may be modified by adding or subtracting two duration objects or by multiplying, dividing, or computing a modulo value of its data member. Numeric multiplication operands may be used as left-hand side or right-hand side operands; in combination with the other multiplication operators the numeric operands must be used as right-hand side operands. Compound assignment operators are also available. Some examples:
minutes fullHour = minutes{ 30 } + halfHour;
fullHour = 2 * halfHour;
halfHour = fullHour / 2;
fullHour = halfHour + halfHour;
halfHour /= 2;
halfHour *= 2;
In addition, duration offers the following members (the first member is an ordinary member function requiring a duration object). The other three are static members (cf. chapter 8) which can be used without requiring objects (as shown at the zero code snippet):
-
Type count() const returns the value that is stored inside the
durationobject's data member. For halfHour it returns 30, not 1800; -
duration<Type, Resolution>::zero(): this is an (immutable) duration object whose count member returns 0. E.g.:
seconds::zero().count(); // equals int64_t 0 -
duration<Type, Resolution>::min(): an immutable duration object whose count member returns the lowest value of its Type (i.e.,
std::numeric_limits<Type>::min()(cf. section 21.11)); -
duration<Type, Resolution>::max(): an immutable duration object whose count member returns the lowest value of its Type (i.e.,
std::numeric_limits<Type>::max()).
Duration objects using different resolutions may be combined as long as no precision is lost. When duration objects using different resolutions are combined the resulting resolution is the finer of the two. When compound binary operators are used the receiving object's resolution must be the finer or the compilation fails.
minutes halfHour{ 30 };
hours oneHour{ 1 };
cout << (oneHour + halfHour).count(); // displays: 90
halfHour += oneHour; // OK
// oneHour += halfHours; // won't compile
The suffixes h, min, s, ms, us, ns can be used for integral values, creating the corresponding duration time intervals. E.g., minutes min = 1h stores 60 in min.
4.2.3: Clocks measuring time
Clocks are used for measuring time. C++ offers several predefined clock types, and all but one of them are defined in the std::chrono namespace. The exception is the clock std::filesystem::__file_clock (see section [4.3.1]({{< relref "/docs/Name Spaces#431-the-__file_clock-type" >}}) for its details).
Before using the chrono clocks the header file must be included.
We need clock types when defining points in time (see the next section). All predefined clock types define the following types:
-
the clock's duration type: Clock::duration (predefined clock types use nanoseconds). E.g.,
system_clock::duration oneDay{ 24h }; -
the clock's resolution type: Clock::period (predefined clock types use nano). E.g.,
cout << system_clock::period::den << '\n'; -
the clock's type that is used to store amounts of time: Clock::rep (predefined clock types use
int64_t). E.g.,system_clock::rep amount = 0; -
the clock's type that is used to store time points (described in the next section):
Clock::time_point(predefined clock types usetime_point<system_clock, nanoseconds>) E.g.,system_clock::time_pointstart.
All clock types have a member now returning the clock type's time_point corresponding to the current time (relative to the clock's epoch). It is a static member and can be used this way: system_clock::time_point tp = system_clock::now().
There are three predefined clock types in the chrono namespace:
- system_clock is the
wall clock, using the system's real time clock; - steady_clock is a clock whose time increases in parallel with the increase of real time;
- high_resolution_clock is the computer's fastest clock (i.e., the clock having the shortest timer-tick interval). In practice this is the same clock as
system_clock.
These clock types also In addition, the __file_clock clock type is defined in the std::filesystem namespace. The epoch time point of __file_clock differs from the epoch time used by the other clock types, but __file_clock has a static member to_sys(__file_clock::time_point) converting __file_clock::time_points to system_clock::time_points (__file_clock is covered in more detail in section [4.3.1](({{< relref "/docs/Name Spaces#431-the-__file_clock-type" >}}))).
In addition to now the classes system_clock and high_resolution_clock (referred to as Clock below) offer these two static members:
-
std::time_t Clock::to_time_t(Clock::time_point const &tp)
a
std::time_tvalue (the same type as returned by C'stime(2)function) representing the same point in time astimePoint. -
Clock::time_point Clock::from_time_t(std::time_t seconds)
a
time_pointrepresenting the same point in time astime_t.
The example illustrates how these functions can be called:
system_clock::from_time_t(
system_clock::to_time_t(
system_clock::from_time_t(
time(0);
)
)
);
4.2.4: Points in time: std::chrono::time_point
Single moments in time can be specified through objects of the class std::chrono::time_point.
Before using the class time_point the <chrono> header file must be included.
Like duration the class time_point requires two template arguments: A clock type and a duration type. Usually system_clock is used as the clock's type using nanoseconds as the default duration type (it may be omitted if nanoseconds is the intended duration type). Otherwise specify the duration type as the time_point's second template argument. The following two time point definitions therefore use identifcal time point types:
time_point<standard_clock, nanoseconds> tp1;
time_point<standard_clock> tp2;
The class time_point supports three constructors:
-
time_point():
the default constructor is initialized to the beginning of the clock's epoch. For
system_clockit is January, 1, 1970, 00:00h, but notice thatfilesystem::__file_clockuses a different epoch (see section 4.3.1 below); -
time_point(time_point<Clock, Duration> const &other):
the
copy constructor(cf. chapter 9) initializes atime_pointobject using the time point defined byother. Ifother's resolution uses a larger period than the period of the constructed object thenother's point in time is represented in the constructed object's resolution (an illustration is provided below, at the description of the membertime_since_epoch); -
time_point(time_point<Clock, Duration> const &&tmp): the
move constructor(cf. chapter 9) acts comparably to thecopy constructor, converting tmp's resolution to the constructed object while moving tmp to the constructed object.
The following operators and members are available:
-
time_point &operator+=(duration const &amount): The
amountof time represented byamountis added to the currenttime_pointobject. This operator is also available as binary arithmetic operator using atime_point const &and aduration const & operand(in any order). Example:system_clock::now() + seconds{ 5 }; -
time_point &operator-=(duration const &amount): The amount of time represented by amount is subtracted from the current
time_pointobject. This operator is also available as binary arithmetic operator using a time_point const & and a duration const & operand (in any order). Example:time_point<system_clock> point = system_clock::now(); point -= seconds{ 5 }; -
duration time_since_epoch() const:
durationis thedurationtype used by the time point object for which this member is called. It returns the amount of time since the epoch that's represented by the object. -
time_point min() const: a static member returning the time point's
duration::minvalue. Example:cout << time_point<system_clock>::min().time_since_epoch().count() << '\n'; // shows -9223372036854775808 -
time_point max() const: a static member returning the time point's
duration::maxvalue.
All predefined clocks use nanoseconds as their time resolution. To express the time in a less precise resolution take one unit of time of the less precise resolution (e.g., hours(1)) and convert it to nanoseconds. Then divide the value returned by the time point's time_since_epoch().count() member by count member of the less precise resolution converted to nanoseconds. Using this procedure the number of hours passed since the beginning of the epoch can be determined:
cout << system_clock::now().time_since_epoch().count() /
nanoseconds(hours(1)).count() <<
" hours since the epoch\n";
Time point objects based on the system clock or on the high resolution clock can be converted to std::time_t (or the equivalent type time_t) values. Such time_t values are used when converting time to text. For such conversions the manipulator put_time (cf. section 6.3.2) is commonly used, but put_time must be provided with the address of a std::tm object, which in turn can be obtained from a std::time_t value. The whole process is fairly complex, and the core elements are visualized in figure 3.
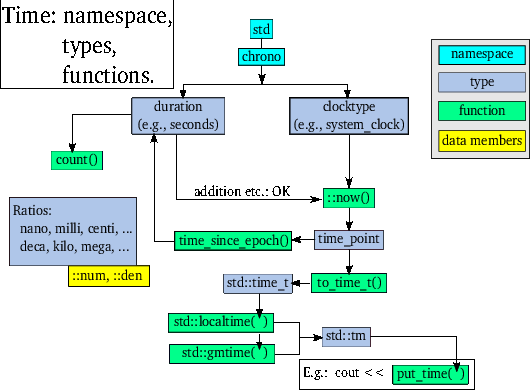
The essential step eventually leading to the insertion of a time point's value into a std::ostream consists of using system_clock::to_time_t(time_point<system_clock> const &tp) to convert a time point to a time_t value (instead of using system_clock the high_resolution_clock can also be used). How a time point can be inserted into a std::ostream is described in section 6.4.4.
4.3: The std::filesystem namespace
Computers commonly store information that must survive reboots in their file systems. Traditionally, to manipulate the file system the C programming language offers functions performing the required system calls. Such functions (like rename(2), truncate(2), opendir(2), and realpath(3)) are of course also available in C++, but their signatures and way of use are often less attractive as they usually expect char const * parameters and may use static buffers or memory allocation based on malloc(3) and free(3).
Since 2003 the Boost library offers wrappers around these functions, offering interfaces to those system calls that are more C++-like.
Currently C++ directly supports these functions in the std::filesystem namespace. These facilities can be used after including the <filesystem> header file.
The filesystem namespace is extensive: it contains more than 10 different classes, and more than 30 free functions. To refer to the identifiers defined in the std::filesystem namespace their fully qualified names (e.g., std::filesystem::path) can be used. Alternatively, after specifying using namespace std::filesystem; the identifiers can be used without further qualifications. Namespace specifications like namespace fs = std::filesystem; are also encountered, allowing specifications like fs::path.
Functions in the filesystem namespace may fail. When functions cannot perform their assigned tasks they may throw exceptions (cf. [chapter 10]) or they may assign values to error_code objects that are passed as arguments to those functions (see section [4.3.2]({{< relref "/docs/Name Spaces#432-the-class-error_code">}}) below).
4.3.1: the __file_clock type
In section [4.3.2]({{< relref "/docs/Name Spaces#432-the-class-error_code">}}) it was stated that various predefined clocks are available, of which the system_clock refers to the clock used by the computer itself. The filesystem namespace uses a different clock: the std::filesystem::__file_clock. Time points obtained using the __file_clock differ from the time points obtained using the system clock: time points using the __file_clock are based on an epoch that (currently) lies well beyond the epoch Jan 1, 00:00:00 1970 that is used by the system clock: Fri Dec 31 23:59:59 2173. The two epochs can be positioned on a time scale with the present somewhere in between:
<------|-----------------------|-----------------------|------->
system_clock's --------> present <-------- __file_clock's
epoch starts positive negative epoch starts
count count
The __file_clock has its own peculiarities: the static member now is available, as are some non-static members: additions and subtractions of durations and the member time_since_epoch can all be used, and . The other members (to_time_t, from_time_t, min and max) aren't available.
Since to_time_t is not available for __file_clock how can we show the time or obtain the time's components of a time_point<__file_clock> object?
Currently, there are two ways to accomplish that: compute the correction by hand or use the static __file_clock::to_sys function converting a __file_clock time point to a time_point as used by system_clock, steady_clock, and high_resolution_clock.
Computing the difference between the epochs we find 6'437'663'999 seconds, which we can add to the obtained time since the __file_clock's epoch to obtain the time since the system_clock's epoch. If timePt holds the duration since the __file_clock epoch then
6'437'663'999 + system_clock::to_time_t(
time_point<system_clock>{ nanoseconds(timePt) })
equals the number of seconds since the system_clock's epoch.
The potential drawback of this procedure is that, as __file_clock's name starts with underscores, the begin of its epoch might change. By using the now members of both clocks this drawback is avoided:
auto systemNow = system_clock::now().time_since_epoch();
auto fileNow = __file_clock::now().time_since_epoch();
time_t diff = (systemNow - fileNow) / 1'000'000'000;
time_t seconds = diff + system_clock::to_time_t(
time_point<system_clock>{ nanoseconds(timePt) });
Although being able to compute the time-shifts yourself is attractive from an understanding point of view, it's maybe also a bit (too) cumbersome for daily practices. The static function __file_clock::to_sys can be used to convert __file_clock::time_points to system_clock:::time_points. The __file_clock::to_sys function is covered in section [4.3.3.2]({{< relref "/docs/Name Spaces/#4332-free-functions" >}}).
4.3.2: The class error_code
Objects of the class std::error_code encapsulate error values, and associated error categories (cf. section 10.9; error_code can be used after including the <system_error> header, but it is also available after including the <filesystem> header file). Traditionally error values are available as values assigned to the global int errno variable. By convention, when errno's value equals zero there's no error. This convention was adopted by error_code.
Error codes can be defined for many conceptually different situations. Those situations are characterized by their own error categories.
Error categories are used to associate error_code objects with the errors that are defined by those categories. Default available error categories may use values like EADDRINUSE (or the equivalent enum class errc value address_in_use) but new types of error categories, tailored to other contexts, can also be defined. Defining error categories is covered near the end of the C++ Annotations (section 23.7.1). At this point two error_category members are briefly introduced:
- std::string message(int err) returning a textual description of error err (like address already in use when
errequalsaddress_in_use). - char const *name() returning the name of the error category (like generic for the generic category);
Error category classes are singleton classes: only one object exists of each error category. In the context of the filesystem namespace the standard category system_category is used, and a reference to the system_category object is returned by the free function std::system_category, expecting no arguments. The public interface of the class error_code declares these construtors and members:
Constructors:
-
error_code() noexcept: the object is initialized with error value 0 and the
system_categoryerror category. Value 0 is not considered an error; -
Copy and move-constructors are available;
-
error_code(int ec, error_category const &cat) noexcept: the object is initialized from error value
ec(e.g.,errno, set by a failing function), and a const reference to the applicable error category (provided by, e.g.,std::system_category()orstd::generic_category()). Here is an example defining anerror_codeobject:error_code ec{ 5, system_category() }; -
error_code(ErrorCodeEnum value) noexcept: this is a member template (cf. section 22.1.3), using
template header template <class ErrorCodeEnum>. It initializes the object with the return value ofmake_error_code(value)(see below). In section 23.7 definingErrorCodeEnumsis covered. Note:ErrorCodeEnumas such does not exist. It is a mere placeholder for existingErrorCodeEnumenumerations;
Members:
The overloaded assignment operator and an assignment operator accepting an ErrorCodeEnum are available;
-
void assign(int val, error_category const &cat): assigns new values to the object's error value and category. E.g, ec.
assign(0, generic_category()); -
error_category const &category() const noexcept: returns a reference to the object's error category;
-
void clear() noexcept: sets the
error_code's value to 0 and its error category tosystem_category; -
error_condition default_error_condition() const noexcept: returns the current category's default error condition initialized with the current object's error value and error category (see section 10.9.2 for details about the class
error_condition); -
string message() const: the message that is associated with the current object's error value is returned (equivalent to
category().message(ec.value())); -
explicit operator bool() const noexcept: returns true if the object's error value is unequal 0 (i.e., it represents and
error) -
int value() const noexcept: returns the object's error value.
Free functions:
Two error_code objects can be compared for (in) equality and can be ordered (using operator<).
Ordering error_codes associated with different error categories has no meaning. But when the error categories are identical then they are compared by their error code values (cf. this SG14 discussion summary);
-
error_code make_error_code(errc value) noexcept: returns an
error_codeobject initialized withstatic_cast<int>(value)andgeneric_category(). This function converts an enumclass errcvalue to anerror_code.Other error related enums may also be defined with which tailored
make_error_codefunctions can be associated (cf. section 23.7;) -
std::ostream &operator<<(std::ostream & os, error_code const &ec): executes the following statement:
return os << ec.category().name() << ':' << ec.value();
Several functions introduced below define an optional last error_code &ec parameter. Those functions have noexcept specifications. If those functions cannot complete their tasks, then ec is set to the appropriate error code, calling ec.clear() if no error was encountered. If no ec argument is provided then those functions throw a filesystem_error exception if they cannot complete their tasks.
4.3.3: Names of file system entries: path
Objects of the class filesysten::path hold names of file system entries. The class path is a value class: a default constructor (empty path) as well as standard copy/move construction/assignment facilities are available. In addition, the following constructors can be used:
- path(string &&tmp);
- path(Type const &source):
any acceptable type that provides the characters of the path (e.g.,
sourceis aNTBS); - path(InputIter begin, InputIter end):
the characters from
begintoenddefine the path's name.
A thus constructed path doesn't have to refer to an existing file system entry.
Path constructors expect character sequences (including NTBSs) that may consist of various (all optional) elements:
- a root-name, e.g., a disk-name (like E:) or device indicator (like //nfs);
- a root-directory, present if it is the first character after the (optional) root-name;
- filename characters (not containing directory separators). In addition the
single dot filename (.)represents the current directory and thedouble dot filename (..)represents the current directory's parent directory; - directory separators (by default the forward slash). Multiple consecutive separators are automatically merged into one separator.
The constructors also define a last format ftmp = auto_format parameter, for which in practice almost never an argument has to be provided (for its details see cppreference.)
Many functions expect path arguments which can usually be created from NTBSs or std::string objects as path allows promotions (cf. section 11.5). E.g., the filesystem function absolute expects a const &path argument. It can be called like this: absolute("tmp/filename").
4.3.3.1: Accessors, modifiers and operators
The class path provides the following operators and members:
Operators:
-
path &operator/=(Type const &arg): the arguments that can be passed to the constructors can also be passed to this member. The
argargument is separated from the path's current content by a directory separator (unless the path is initially empty as in cout << path{}.append("entry")). See also the membersappendandconcat, below. The free operator/accepts twopath(promotable) arguments, returning apathcontaining both paths separated by a directory separator (e.g.,lhs / rhsreturns a path object containinglhs/rhs); -
path &operator+=(Type const &arg): similar to
/=, but no directory separator is used when addingargto the currentpath; -
comparison operators:
pathobjects can be compared using the (operators implied by the)==and<=>operators. Path objects are compared by lexicographical comparing theirascii-charactercontent.
Accessors:
Accessors return specific path components. If a path doesn't contain the requested component then an empty path is returned.
-
char const *c_str(): the path's content as an
NTBSis returned; -
path extension() returns the dot-extension of the path's last component (including the dot);
-
path filename() returns the last path-content of the current
pathobject. See also thestem()accessor, below; -
bool is_absolute(): returns true if the
pathobject contains an absolute path specification; -
bool is_relative(): returns true if the
pathobject contains a relative path specification; -
path parent_path() returns the current path-content from which the last element has been removed. Note that if the
pathobject contains a filename's path (like"/usr/bin/zip") thenparent_pathremoves/zipand returns/usr/bin, so notzip's parent directory, but its actual directory; -
path relative_path(): returns the path's content beyond the path's root-directory component of the
pathobject. E.g., if the pathulb{ "/usr/local/bin" }is defined thenulb.relative_path()returns a path containing"usr/local/bin"; -
path root_directory(): returns the root-directory component of the
pathobject; -
path root_name(): returns the root-name's component of the
pathobject; -
path root_path(): returns the root-path component of the
pathobject; -
path stem() returns the last path-content of the current
pathobject from which thedot-extensionhash been removed; -
string(): returns the path's content as a
std::string.Similar accessors are available for the following string-types:
wstring,u8string,u16string,u32string,generic_string,generic_wstring,generic_u8string,generic_u16string, andgeneric_u32string;
Except for the family of string() and the is_... accessors, there are also bool has_... members returning true if the path contains the specified component (e.g., has_extension returns true if the path contains an extension).
Member functions:
-
path &append(Type const &arg) acts like the
/=operator; -
path::iterator begin() returns an iterator containing the first path component; Dereferencing a
path::iteratorreturns a path object.When available root names and root directories are returned as initial components. When incrementing
path::iteratorsthe individual directories and finally filename components are returned. The directory separators themselves are not returned when dereferencing subsequentpath::iterators; -
void clear(): the path's content is erased;
-
int compare(Type const &other):
returns the result of lexicographically comparing the current
path's content withother.Othercan be apath, astring-typeor anNTBS; -
path &concat(Type const &arg) acts like the
+=operator; -
ostream &operator<<(ostream &out, path const &path) (stream insertion) inserts
path's content, surrounded by double quotes, intoout; -
istream &operator>>(istream &in, path &path) extracts path's content from in. The extracted path name may optionally be surrounded by double quotes. When inserting a previously extracted path object only one set of surrounding quotes are shown.
-
path &remove_filename(): removes the last component of the stored path. If only a root-directory is stored, then the root directory is removed. Note that the last directory separator is kept, unless it is the only path element;
-
path &replace_extension(path const &replacement = path{} ):
replaces the extension of the last component of the stored path (including the extension's dot) with
replacement. The extension is removed ifreplacementis empty. If thepathcallingreplace_extensionhas no extension thenreplacementis added. Thereplacementmay optionally start with a dot. Thepathobject's extension receives only one dot; -
path &replace_filename(path const &replacement):
replaces the last component of the stored path with
replacement, which itself may contain multiple path elements. If only a root-directory is stored, then it is replaced byreplacement. The member's behavior is undefined if the current path object is empty;
4.3.3.2: Free functions
In addition to the path member functions various free functions are available. Some of these copy files. Those functions accept an optional std::filesystem::copy_options argument. The enum class copy_options defines symbolic constants that can be used to fine-tune the behavior of these functions. The enumeration supports bitwise operators (the symbols' values are shown between parentheses) and defines these symbols:
- When copying files:
- none (0): report an error (default behavior);
- skip_existing (1): keep the existing file, without reporting an error;
- overwrite_existing (2): replace the existing file;
- update_existing (4): replace the existing file only if it is older than the file being copied;
- When copying subdirectories:
- none (0): skip subdirectories (default behavior);
- recursive (8): recursively copy subdirectories and their content;
- When copying symlinks:
- none (0): follow symlinks (default behavior);
- copy_symlinks (16): copy symlinks as symlinks, not as the files they point to;
- skip_symlinks (32): ignore symlinks;
- To control copy's behavior itself:
- none (0): copy file content (default behavior);
- directories_only (64): copy the directory structure, but do not copy any non-directory files;
- create_symlinks (128): instead of creating copies of files, create symlinks pointing to the originals (the source path must be an absolute path unless the destination path is in the current directory);
- create_hard_links (256): instead of creating copies of files, create hardlinks that resolve to the same files as the originals.
The following functions expect path arguments:
-
path absolute(path const &src, [, error_code &ec]): a copy of
srcspecified as an absolute path (i.e., starting at the filesystem's root (and maybe disk) name). It can be called like this:absolute("tmp/filename"), returning the (absolute) current working directory to whichabsolute's argument is appended as a final element, separated by a directory separator. Relative path indicators (like../and./) are kept. The returned path merely is an absolute path. If relativepathindicators should be removed, then use the next function; -
path canonical(path const &src [, error_code &ec]): returns
src's canonical path. The argumentsrcmust refer to an existing directory entry. Example:path man{ "/usr/local/bin/../../share/man" }; cout << canonical(man) << '\n'; // shows: "/usr/share/man" -
void copy(path const &src, path const &dest [, copy_options opts [, error_code &ec]]):
srcmust exist. Copiessrctodestif thecpprogram would also succeed.If
srcis a directory, anddestdoes not exist,destis created. Directories are recursively copied if copy options recursive or none were specified; -
bool copy_file(path const &src, path const &dest [, copy_options opts [, error_code &ec]]):
srcmust exist. Copiessrctodestif thecpprogram would also succeed. Symbolic links are followed. The value true is returned if copying succeeded; -
void copy_symlink(path const &src, path const &dest [, error_code &ec]): creates the symlink
destas a copy of the symlinksrc; -
bool create_directories(path const &dest [, error_code &ec]): creates each component of
dest, unless already existing. The value true is returned ifdestwas actually created. If false is returnedeccontains anerror-code, which is zero (ec.value() == 0) ifdestalready existed. See alsocreate_directorybelow; -
bool create_directory(path const &dest [, path const &existing] [, error_code &ec]):
dest's parent directory must exist. This function creates directorydestif it does not yet exist. The value true is returned ifdestwas actually created. If false is returned ec contains an error-code, which is zero (ec.value() == 0) ifdestalready existed. Ifexistingis specified, thendestreceives the same attributes asexisting; -
void create_directory_symlink(path const &dir, path const &link [, error_code &ec]): like
create_symlink(see below), but is used to create a symbolic link to a directory; -
void create_hardlink(path const &dest, path const &link [, error_code &ec]): creates a hard link from
linktodest.destmust exist; -
void create_symlink(path const &dest, path const &link [, error_code &ec]): creates a symbolic (soft) link from
linktodest;destdoes not have to exist; -
path current_path([error_code &ec]), void current_path(path const &toPath [, error_code &ec]): the former function returns the current working directory (
cwd), the latter changes thecwdtotoPath. The returnedpath's last character is not a slash, unless called from the root-directory; -
bool equivalent(path const &path1, path const &path2 [, error_code &ec]): true is returned if
path1andpath2refer to the same file or directory, and have identical statuses. Both paths must exist; -
bool exists(path const &dest [, error_code &ec]), exists(file_status status): true is returned if
destexists (actually: ifstatus(dest[, ec])(see below) returns true). Note: when iterating over directories, the iterator usually provides the entries' statuses. In those cases callingexists(iterator->status())is more efficient than callingexists(*iterator). Whendestis the path to a symbolic reference then exists returns whether the link's destination exists or not (see also the functionsstatusandsymlink_statusin section [4.3.4]({{< relref "/docs/Name Spaces/#434-handling-directories-directory_entry" >}})); -
std::unintmax_t file_size(path const &dest [, error_code &ec]): returns the size in bytes of a regular file (or symlink destination);
-
std::uintmax_t hard_link_count(path const &dest [, error_code &ec]): returns the number of hard links associated with
dest; -
time_point<__file_clock> last_write_time(path const &dest [, error_code &ec]), void last_write_time(path const &dest, time_point<__file_clock> newTime [, error_code &ec]): the former function returns
dest's last modification time; the latter function changesdest's last modification time to newTime.last_write_time's return type is defined through a using alias forchrono::time_point(cf. section 4.2.4). The returnedtime_pointis guaranteed to cover all file time values that may be encountered in the current file system. The function__file_clock::to_sys(see below) can be used to convert__file_clocktime points tosystem_clock time_points; -
path read_symlink(path const &src [, error_code &ec]):
srcmust refer to a symbolic link or an error is generated. The link's target is returned; -
bool remove(path const &dest [, error_code &ec]), std::uintmax_t remove_all(path const &dest [, error_code &ec]):
removeremoves the file, symlink, or empty directorydest, returning true ifdestcould be removed;remove_allremovesdestif it's a file (or symlink); and recursively removes directorydest, returning the number of removed entries; -
void rename(path const &src, path const &dest [, error_code &ec]): renames
srctodest, as if using the standardmv(1)command (ifdestexists it is overwritten); -
void resize_file(path const &src, std::uintmax_t size [, error_code &ec]):
src's size is changed tosizeas if using the standardtruncate(1)command; -
space_info space(path const &src [, error_code &ec]): returns information about the file system in which
srcis located; -
path system_complete(path const &src[, error_code& ec]): returns the absolute path matching
src, usingcurrent_pathas its base; -
path temp_directory_path([error_code& ec]): returns the path to a directory that can be used for temporary files. The directory is not created, but its name is commonly available from the environment variables
TMPDIR,TMP,TEMP, orTEMPDIR. Otherwise,/tmpis returned. -
time_point<system_clock> __file_clock::to_sys(time_point<__file_clock> timePoint): here is how the time returned by
last_write_timecan be represented using thesystem_clock's epoch:int main() { time_t seconds = system_clock::to_time_t( __file_clock::to_sys(last_write_time("lastwritetime.cc")) ); cout << "lastwritetime.cc's last (UTC) write time: " << put_time(gmtime(&seconds), "%c") << '\n'; }
4.3.4: Handling directories: directory_entry
The file system is a recursive data structure. Its top-level entry is a directory (the root directory) containing plain directory entries (files, (soft) links, named sockets, etc.) and possibly also (sub)directory entries referring to nested directories which in turn may contiain plain- and (sub)directory entries.
In the std::filesystem namespace the elements of directories are objects of the class directory_entry, containing names and statuses of the entries of that directory.
The class directory_entry supports all standard constructors and assignment operators and in addition a constructor expecting a path:
directory_entry(path const &entry);
Objects of the class directory_entry can be constructed by name, without requiring that those objects refer to existing entries in the computer's file system. The assignment operator is also available, as is the (ostream) insertion operator, inserting the object's path into the stream. The extraction operator is not available.
directory_entry objects may be compared using the ==, !=, <, <=, >, and >= operators. These operators are then applied to their path objects: directory_entry("one") == directory_entry("one") returns true.
In addition to these operators the class directory_entry also has these member functions:
-
void assign(path const &dest): the current path is replaced by
dest(its action is identical to that of the overloaded assignment operator); -
void replace_filename(path const &dest): the last element of the current object's path is replaced by dest. If that element is empty (like when the object's path ends in a directory separator) then dest is appended to the current object's path;
-
path const &path() const, operator path const &() const: the current object's path name is returned;
-
filesystem::file_status status([error_code &ec]): returns type and attributes of the directory entry referred to by the current object. If the current object refers to a symlink then the status of the entry the symlink refers to is returned. To obtain the status of the entry itself, even if it's a symlink use
symlink_status(see also section [4.3.5]({{< relref "/docs/Name Spaces/#435-types-file_type-and-permissions-perms-of-file-system-elements-file_status" >}}) and [4.3.5.1]({{< relref "/docs/Name Spaces/#4351-obtaining-the-status-of-file-system-entries" >}}) below).
4.3.4.1: Visiting directory entries: (recursive_)directory_iterator
The filesystem namespace has two classes simplifying directory processing: objects of the class directory_iterator are (input) iterators iterating over the entries of directories; and objects of the class recursive_directory_iterator are (input) iterators recursively visiting all entries of directories.
The classes (recursive_)directory_iterator provides default, copy, and move constructors. Objects of both classes may also be constructed from a path and an optional error_code. E.g.,
directory_iterator(path const &dest [, error_code &ec]);
All members of standard input iterators (cf. section 18.2) are supported. These iterators point to directory_entry objects referring to entries in the computer's file system. E.g.,
cout << *directory_iterator{ "/home" } << '\n'; // shows the first
// entry under /home
End-iterators matching these objects are available through the default constructed objects of the two classes. In addition, range-based for loops can be used as shown by the next example:
for (auto &entry: directory_iterator("/var/log"))
cout << entry << '\n';
For-statements explicitly defining iterators can also be used:
for (
auto iter = directory_iterator("/var/log"),
end = directory_iterator{};
iter != end;
++iter
)
cout << entry << '\n';
After constructing a (recursive_)directory_iterator base{"/var/log"} object it refers to the first element of its directory. Such iterators can also explicitly be defined: auto &iter = begin(base), auto iter = begin(base), auto &iter = base or auto iter = base. All these iter objects refer to base's data, and incrementing them also advances base to its next element:
recursive_directory_iterator base{ "/var/log/" };
auto iter = base;
// final two elements show identical paths,
// different from the first element.
cout << *iter << ' ' << *++iter << ' ' << *base << '\n';
The functions begin and end that are used in the above examples are, like (recursive_)directory_iterator, available in the filesystem namespace.
The recursive_directory_iterator also accepts a directory_options argument (see below), by default specified as directory_options::none:
recursive_directory_iterator(path const &dest,
directory_options options [, error_code &ec]);
The enum class directory_options defines values that are used to fine-tune the behavior of recursive_directory_iterator objects, supporting bitwise operators (the values of its symbols are shown between parentheses):
- none (0): directory symlinks are skipped, denied permission to enter a subdirectory generates an error;
- follow_directory_symlink (1): symlinks to subdirectories are followed;
- skip_permission_denied (2): directories that cannot be entered are silently skipped.
The class recursive_directory_iterator also has these members:
-
int depth() const:
returns the current iteration depth. The depth of the initial directory, specified at construction-time, equals 0;
-
void disable_recursion_pending():
when called before incrementing the iterator the next directory entry is not recursively visited if it is a sub-directory. Then, after incrementing the iterator recursion is again allowed. If a recursion should end at a specific depth then this function must repeatedly be called before calling the iterator's increment operator once
depth()returns that specific depth; -
recursive_directory_iterator &increment(error_code &ec):
acts identically to the iterator's increment operator. However, when an error occurs
operator++throws afilesystem_errorexception, whileincrementassigns the error toec; -
directory_options options() const:
returns the
option(s)specified at construction-time; -
void pop():
ends processing the current directory, and continues at the next entry in the current directory's parent. When (in a for-statement, see the example below) called from the initial directory that directory's processing ends;
-
bool recursion_pending() const:
true is returned if recursive processing of sub-directories of the currently processed directory is allowed. If so, and the directory entry the iterator points at is a sub-directory then processing continues at that sub-directory at the iterator's next increment;
Here is a little program displaying all directory elements of a directory and of all its immediate sub-directories.
int main()
{
recursive_directory_iterator base{ "/var/log" };
for (auto entry = base, endIt = end(base); entry != endIt; ++entry)
{
cout << entry.depth() << ": " << *entry << '\n';
if (entry.depth() == 1)
entry.disable_recursion_pending();
}
}
The above program handles entries as they come. If other strategies are needed they have to be implemented. E.g., a breadth-first strategy first visits all the non-directory entries and then visits the sub-directories. In the next example this is realized by processing each of the directories stored in level (initially it merely contains the starting directory). Processing a directory means that its non-directory entries are directly processed while the names of its sub-directories are stored in next. Once all entries in level have been processed the names of the next level sub-directories are available in next and by assigning next to level all directories at the next level are processed. When reaching the most deeply nested sub-directories next remains empty and the while statement ends:
void breadth(path const &dir) // starting dir.
{
vector<path> level{ dir }; // currently processed level
while (not level.empty()) // process all its dirs.
{
vector<path> next; // dirs of the next level
for (auto const &dir: level) // visit all dirs at this level
{
cout << "At " << dir << '\n';
// at each dir: visit all entries
for (auto const &entry: directory_iterator{ dir })
{
if (entry.is_directory()) // store all dirs at the current
next.push_back(entry); // level
else // or process its non-dir entry
cout << " entry: " << entry << '\n';
}
}
level = next; // continue at the next level,
} // which eventually won't exist
}
4.3.5: Types (file_type) and permissions (perms) of file system elements: file_status
File system entries (represented by path objects), have several attributes: permissions (e.g., the owner may modifiy an entry, others may only read entries), and types (like plain files, directories, and soft-links).
Types and permissions of file system entries are available through objects of the class file_status. The class file_status is a value-class supporting copy- and move- constructors and assignment operators.
The constructor
explicit file_status(file_type type = file_type::none,
perms permissions = perms::unknown)
creates the file status for a specific type of file system entry having a specific set of permissions. It also acts as default constructor.
The constructor's first parameter is an enumeration specifying the type of a file system entry represented by a path object:
- not_found = -1 indicates that a file system entry whose status was requested was not found (this is not considered an error);
- none indicates either that the file status has not yet been evaluated, or that an error occurred when an entry's status was evaluated;
- regular: the entry is a regular file;
- directory: the entry is a directory;
- symlink: the entry is a symbolic link;
- block: the entry is a block device;
- character: the entry is a character device;
- fifo: the entry is a named pipe;
- socket: the entry is a socket file;
- unknown: the entry is an unknown file type
The constructor's second parameter defines the enum class perms specifying the access permissions of file system entries. The enumeration's symbols were selected so that their meanings should be more descriptive than the constants defined in the <sys/stat.h> header file, but other than that they have identical values. All bitwise operators can be used by values of the enum class perms. Here is an overview of the symbols defined by the enum class perms:
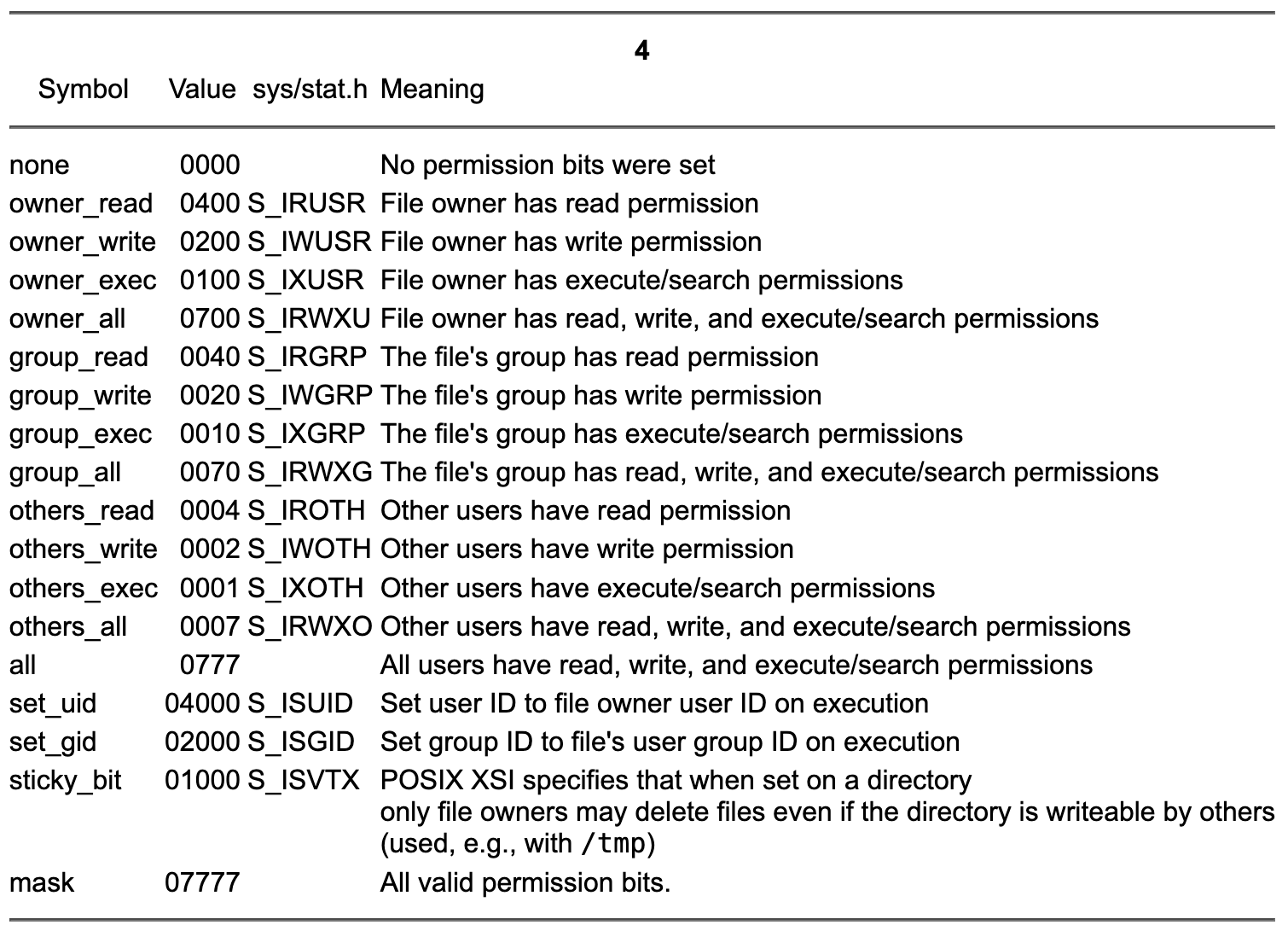
The class file_status provides these members:
-
perms permissions() const and void permissions(perms newPerms [, perm_options opts] [, error_code &ec]):
the former member returns the permissions of the file system entry represented by the
file_statusobject, the latter can be used to modify those permissions. The enum classperm_optionshas these values:- replace: current options are replaced by newPerms;
- add: newPerms are added to the current permissions;
- remove: newPerms are removed from the current permissions;
- nofollow: when path refers to a symbolic link the permissions of the symbolic link instead of those of the file system entry the link refers to are updated.
-
file_type type() const and void type(file_type type):
the former member returns the type of the file system entry represented by the
file_statusobject, the latter can be used to set the type.
4.3.5.1: Obtaining the status of file system entries
The filesystem functions status and symlink_status retrieve or change statuses of file system entries. These functions may be called with a final (optional) error_code argument which is assigned an appropriate error code if they cannot perform their tasks. If the argument is omitted the members throw exceptions if they cannot perform their tasks:
-
file_status status(path const &dest [, error_code &ec]):
returns type and attributes of
dest. Ifdestis a symlink the status of the link's destination is returned; -
file_status symlink_status(path const &dest [, error_code &ec]):
when calling
symlink_status(dest)the status ofdestitself is returned. Thus, ifdestrefers to a symlink then symlink_status does not return the status of the entrydestrefers to, but the status ofdestitself: a symbolic link (withfile_status'stype()member returningfile_type::symlink); -
bool status_known(file_status const &status):
returns true if
statusrefers to a determinedstatus(statusitself may indicate that the entity referred to bystatusdoes not exist). One way of receiving false is by passing it a default status object:status_known(file_status{});
Once a file_status object is obtained the file type of the entry whose status it represents can be interrogated using these functions (defined in the filesystem namespace, where WHATEVER is the requested specification):
bool is_WHATEVER(file_status status)
bool is_WHATEVER(path const path &entry [, error_code &ec])
These functions return true if status or status matches the requested type. Here are the available functions:
- is_block_file: the path refers to a block device;
- is_character_file: the path refers to a character device;
- is_directory: the path refers to a directory;
- is_empty: the path refers to an empty file or directory;
- is_fifo: the path refers to a named pipe;
- is_other: the path does not refer to a directory, regular file or symlink;
- is_regular_file: the path refers to a regular file;
- is_socket: the path refers to a named socket;
- is_symlink: the path refers to a symbolic link;
Alternatively, the file_status::type() member can be used in, e.g., a switch to select an entry matching its file_type return value (see the previous section ([4.3.5]({{< relref "/docs/Name Spaces/#435-types-file_type-and-permissions-perms-of-file-system-elements-file_status" >}})) for a description of the symbols defined by the file_type enum).
Here is a little program showing how file statuses can be obtained and shown (for the map see section 12.4.7):
namespace
{
std::unordered_map<file_type, char const *> statusMap =
{
{ file_type::not_found, "an unknown file" },
{ file_type::none, "not yet or erroneously evaluated "
"file type" },
{ file_type::regular, "a regular file" },
{ file_type::directory, "a directory" },
{ file_type::symlink, "a symbolic link" },
{ file_type::block, "a block device" },
{ file_type::character, "a character device" },
{ file_type::fifo, "a named pipe" },
{ file_type::socket, "a socket file" },
{ file_type::unknown, "an unknown file type" }
};
}
int main()
{
cout << oct;
string line;
while (true)
{
cout << "enter the name of a file system entry: ";
if (not getline(cin, line) or line.empty())
break;
path entry{ line };
error_code ec;
file_status stat = status(entry, ec);
if (not status_known(stat))
{
cout << "status of " << entry << " is unknown. "
"Ec = " << ec << '\n';
continue;
}
cout << "status of " << entry << ": type = " <<
statusMap[stat.type()] <<
", permissions: " <<
static_cast<size_t>(stat.permissions()) << '\n';
}
}
4.3.6: Information about the space of file systems: space_info
Every existing path lives in a file system, Sizes of file systems typically are quite large, but there is a limit to their sizes.
The size of file systems, the number of bytes that is currently being used and the remaining number of bytes is made available by the function space(path const &entry [, error_code &ec]), returning the information about the file system containing entry in a POD struct space_info.
If the error_code argument is provided then it is cleared if no error occurs, and set to the operating system's error code if an error has occurred. If an error occurs and the error_code argument was not provided then a filesystem_error exception is thrown, receiving path as its first argument and the operating system's error code as its error_code argument.
The returned space_info has three fields:
uintmax_t capacity; // total size in bytes
uintmax_t free; // number of free bytes on the file system
uintmax_t available; // free bytes for a non-privileged process
If a field cannot be determined it is set to -1 (i.e., the max. value of the type uintmax_t).
The function can be used this way:
int main()
{
path tmp{ "/tmp" };
auto pod = space(tmp);
cout << "The filesystem containing /tmp has a capacity of " <<
pod.capacity << " bytes,\n"
"i.e., " << pod.capacity / (1024 * 1024) << " MB.\n"
"# free bytes: " << pod.free << "\n"
"# available: " << pod.available << "\n"
"free + available: " << pod.free + pod.available << '\n';
}
4.3.7: File system exceptions: filesystem_error
The std::filesystem namespace offers its own exception type filesystem_error (see also chapter 10). Its constructor has the following signature (the bracketed parameters are optional):
filesystem_error(string const &what,
[path const &path1, [path const &path2,]]
error_code ec);
As filesystem facilities are closely related to standard system functions, errc error code enumeration values can be used to obtain error_codes to pass to filesystem_error, as illustrated by the following program:
int main()
try
{
try
{
throw filesystem_error{ "exception encountered", "p1", "p2",
make_error_code(errc::address_in_use) };
}
catch (filesystem_error const &fse)
{
cerr << "what: " << fse.what() << "\n"
"path1: " << fse.path1() << "\n"
"path2: " << fse.path2() << "\n"
"code: " << fse.code() << '\n';
throw;
}
}
catch (exception const &ec)
{
cerr << "\n"
"plain exception's what: " << ec.what() << "\n\n";
}