You cannot select more than 25 topics
Topics must start with a letter or number, can include dashes ('-') and can be up to 35 characters long.
This file contains ambiguous Unicode characters that may be confused with others in your current locale. If your use case is intentional and legitimate, you can safely ignore this warning. Use the Escape button to highlight these characters.
# 缓存
## 缓存有3大问题, ?
### 缓存雪崩
缓存雪崩是指缓存中数据大批量到过期时间, , ,
解决办法:
- 缓存过期时间设置成随机
- 热点数据考虑永不过期(定时刷新)
- 使用分布式缓存,防止单点故障缓存全部丢失
### 缓存穿透
缓存穿透是指缓存和数据库中都没有的数据, , ,
解决办法:
- 空对象
- 布隆过滤器
### 缓存击穿
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力
解决办法:
- 热点数据永不过期(后台进程定时刷新)
- 加互斥锁
## 缓存有哪些淘汰策略?
- 先进先出策略 FIFO( , )
如果一个数据最先进入缓存中,则应该最早淘汰掉
- 最近最少使用策略 LRU( )
如果数据最近被访问过, , , , , ,
- 最少使用策略 LFU( )
如果一个数据在最近一段时间内使用次数很少,那么在将来一段时间内被使用的可能性也很小。对于交替出现的数据,缓存命中不高
## 读写屏障是怎么回事?
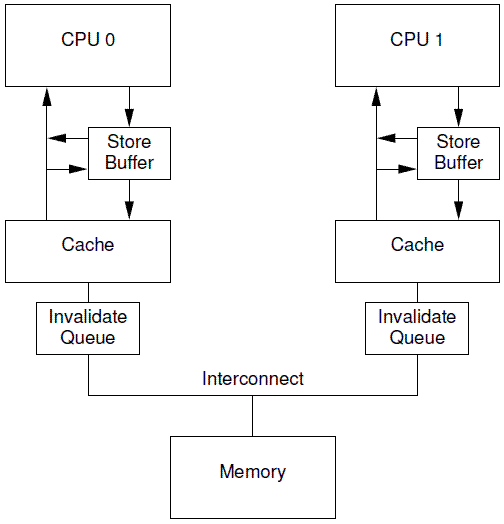
内存屏障分为读屏障(rmb)与写屏障(wmb)。写屏障主要保证在写屏障之前的在Store buffer中的指令都真正的写入了缓存。读屏障主要保证了在读屏障之前所有Invalidate queue中所有的无效化指令都执行。有了读写屏障的配合, ,
## 缓存一致性
** 对于读是不存在缓存与数据库不一致的的情况**。读的流程:
- 如果我们的数据在缓存里边有,那么就直接取缓存的。
- 如果缓存里没有我们想要的数据,我们会先去查询数据库,然后将数据库查出来的数据写到缓存中。
- 最后将数据返回给请求
对于数据库更新操作, 执行操作时候,两种选择:
- 先操作数据库,再操作缓存
- 先操作缓存,再操作数据库
操作缓存,两种方案选择:
- 更新缓存
- 删除缓存
一般我们都是采取删除缓存缓存策略的,原因:
- 高并发环境下,无论是先操作数据库还是后操作数据库而言,如果加上更新缓存,那就更加容易导致数据库与缓存数据不一致问题。(删除缓存直接和简单很多)
- 如果每次更新了数据库,都要更新缓存【这里指的是频繁更新的场景,这会耗费一定的性能】,倒不如直接删除掉。等再次读取时,缓存里没有,那我到数据库找,在数据库找到再写到缓存里边 (体现懒加载)
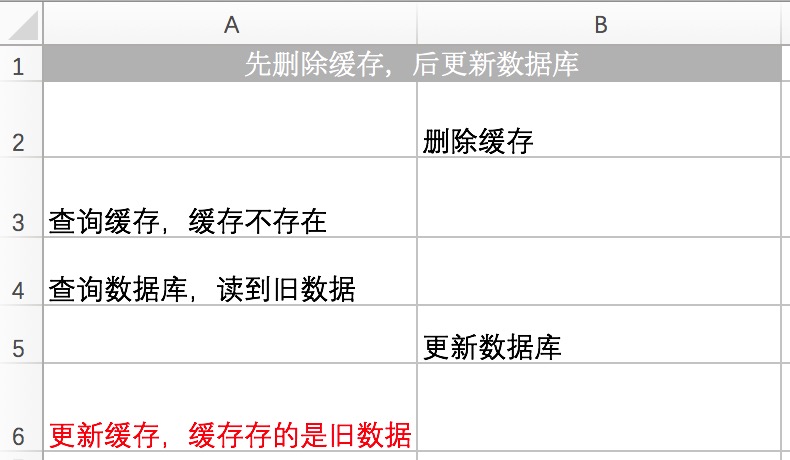
** 先删缓存,再更新数据库**
该方案会导致不一致的原因是。同时有一个请求A进行更新操作,
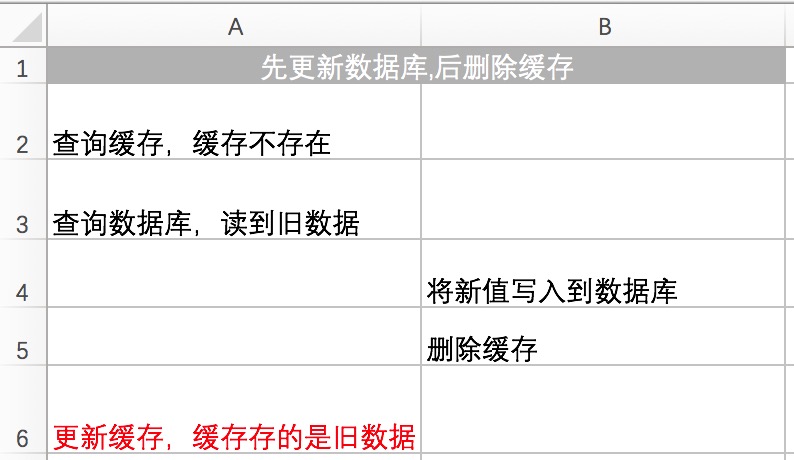
** 先更新数据,再删除缓存:**
如果在高并发的场景下,出现数据库与缓存数据不一致的概率特别低,也不是没有:
解决办法:
- Cache Aside Pattern

- binlog模式
