|
|
# ElasticSearch
|
|
|
|
|
|
## 什么是ElasticSearch?
|
|
|
|
|
|
Elasticsearch是基于Apace Lunence构建的开源,分布式,具有高可用性和高拓展性的全文检索引擎。Elasticsearch具有开箱即用的特性,提供RESTful接口,是面向文档的数据库,文档存储格式为JSON,可以水平扩展至数以百计的服务器存储来实现处理PB级别的数据。
|
|
|
|
|
|
## ES有哪些节点类型?
|
|
|
|
|
|
一个节点就是一个Elasticsearch的实例,每个节点需要显示指定节点名称,可以通过配置文件配置,或者启动时候`-E node.name=node1`指定
|
|
|
|
|
|
#### 节点类型
|
|
|
|
|
|
每个节点在集群承担承担不同的角色,也可以称为节点类型。
|
|
|
|
|
|
**候选主节点(Master-eligible nodes)和主节点(Master Node)**
|
|
|
|
|
|
- 每个节点启动之后,默认就是一个Master eligible节点,Master-eligible节点可以参加选主流程,成为Master节点
|
|
|
- 当第一个节点启动时候,它会将自己选举成为Master节点
|
|
|
- 在每个节点上都保存了集群的状态信息,但**只有Master节点才能修改集群的状态信息**。集群状态(Cluster State)中必要信息包含
|
|
|
- 所有节点的信息
|
|
|
- 所有的索引,以及其Mapping与Setting信息
|
|
|
- 分片的路由信息
|
|
|
|
|
|
**数据节点(Data Node)和协调节点(Coordinating Node)和Ingest节点**
|
|
|
|
|
|
- Data Node
|
|
|
- **用于保存数据的节点。负责保存分片的数据,在数据拓展上起到至关重要的作用**
|
|
|
- Coorination Node
|
|
|
- **负责接受Client的请求,将请求分发到合适的节点,最终把结果汇集到一起**
|
|
|
- **每个节点默认都起到Cooridinating Node的职责**,这就意味着如果一个node,将node.master,node.data,node.ingest全部设置为false,那么它就是一个纯粹的coordinating Node node,仅仅用于接收客户端的请求,同时进行请求的转发和合并
|
|
|
- Ingest节点
|
|
|
- 用于预处理,可以运行pipeline脚本,用来对document写入索引文件之前进行预处理的
|
|
|
|
|
|
在生产环境部署上可以部署独立(dedicate)的 Ingest Node 和 Coordinate node,在前端的Load Balance前面增加转发规则把读分发到coording node,写分发到 ingest node。 如果集群负载不高,可以配置一些节点同时具备coording和ingest的能力。然后将读写全部路由到这些节点。不仅配置简单,还节约硬件成本
|
|
|
|
|
|
**其他类型节点**
|
|
|
|
|
|
- 冷热节点(Hot & Warm Node)
|
|
|
- 不同硬件配置的Data Node,用来实现Hot & Warm架构,降低集群部署的成本。通过设置节点属性来实现
|
|
|
|
|
|
- 机器学习节点(Machine Learning Node)
|
|
|
- 负责跑机器学习的Job,用来异常检测
|
|
|
|
|
|
配置原则:
|
|
|
|
|
|
- 开发环境一个节点可以承担多种角色,节省服务器资源
|
|
|
- 生产环境中,应该设置单一的角色的节点,即dedicated node
|
|
|
|
|
|
|
|
|
节点类型 | 配置参数 | 默认值
|
|
|
---|---|----
|
|
|
候选主节点 | node.master | true
|
|
|
数据节点 | node.data | true
|
|
|
ingest节点 | node.ingest | true
|
|
|
协调节点 | 无 | 每个节点默认都是协调节点
|
|
|
机器学习节点 | node.ml | true
|
|
|
|
|
|
## 为什么说ES是准实时的?
|
|
|
|
|
|
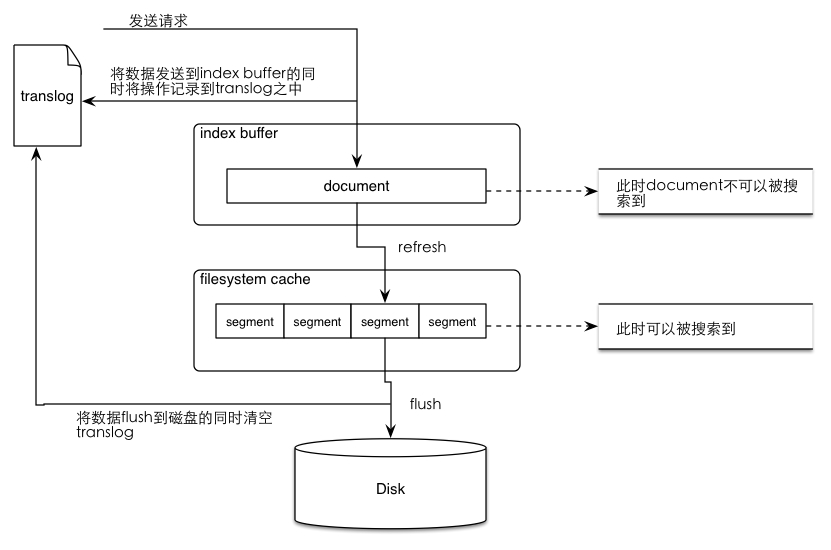
|
|
|
Document首先写入到Indexing buffer中,当 buffer 中的数据每隔index.refresh_interval秒(或者Indexing buffer满了)缓存 refresh 到filesystem cache 中时,此时文档是可以检索到了
|
|
|
|
|
|
## 怎么解决ES深度分页问题?
|
|
|
|
|
|
深度分页指的是假设我们请求第 1000 页—结果从 10001 到 10010 。所有都以相同的方式工作除了每个分片不得不产生前10010个结果以外。 然后协调节点对全部 50050 个结果排序最后丢弃掉这些结果中的 50040 个结果。在分布式系统中,对结果排序的成本随分页的深度成指数上升。
|
|
|
|
|
|
解决办法就是业务上面避免。
|
|
|
|
|
|
## doc values为了解决什么?
|
|
|
|
|
|
doc_values是为了解决排序和聚合问题。doc_values不适合text类型字段,对于text类型字段需要使用Fielddata
|
|
|
|
|
|
```
|
|
|
PUT /myindex/_mapping/doc
|
|
|
{
|
|
|
"properties": {
|
|
|
"myfield": {
|
|
|
"type": "text",
|
|
|
"fields":{
|
|
|
"keyword":{
|
|
|
"type":"keyword",
|
|
|
"ignore_above":256
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
```
|
|
|
|
|
|
上面myfield是不可以聚合的,但是myfield.keyword是可以聚合的
|
|
|
|
|
|
## ES中副本分片的目的是做什么?
|
|
|
|
|
|
1. 副本分片的主要目的就是为了故障转移,如果持有主分片的节点挂掉了,一个副本分片就会晋升为主分片的角色。
|
|
|
|
|
|
2. 副本分片可以服务于读请求,可以通过增加副本的数目来提升查询性能
|
|
|
|
|
|
## 怎样在不停机情况下,进行索引重建?
|
|
|
|
|
|
索引别名
|
|
|
|
|
|
## ES数据建模有哪些模式?
|
|
|
|
|
|
加入我们正在根据用户名称,搜索其博客文章
|
|
|
|
|
|
### 应用层联接
|
|
|
|
|
|
根据user索引搜索到用户id,然后根据id去搜索文章索引blogpost
|
|
|
|
|
|
```
|
|
|
PUT /my_index/user/1
|
|
|
{
|
|
|
"name": "John Smith",
|
|
|
"email": "john@smith.com",
|
|
|
"dob": "1970/10/24"
|
|
|
}
|
|
|
|
|
|
PUT /my_index/blogpost/2
|
|
|
{
|
|
|
"title": "Relationships",
|
|
|
"body": "It's complicated...",
|
|
|
"user": 1
|
|
|
}
|
|
|
```
|
|
|
|
|
|
### 反范式设计
|
|
|
|
|
|
用于1对多模式下,将1的信息,存放在N这一边。下面就是把用户信息存放一份在blogpost这里面
|
|
|
|
|
|
```
|
|
|
PUT /my_index/user/1
|
|
|
{
|
|
|
"name": "John Smith",
|
|
|
"email": "john@smith.com",
|
|
|
"dob": "1970/10/24"
|
|
|
}
|
|
|
|
|
|
PUT /my_index/blogpost/2
|
|
|
{
|
|
|
"title": "Relationships",
|
|
|
"body": "It's complicated...",
|
|
|
"user": {
|
|
|
"id": 1,
|
|
|
"name": "John Smith"
|
|
|
}
|
|
|
}
|
|
|
```
|
|
|
|
|
|
### 嵌套对象
|
|
|
|
|
|
假定们可以将一篇博客文章的评论以一个 comments 数组的形式和博客文章放在一起:
|
|
|
|
|
|
```
|
|
|
PUT /my_index/blogpost/1
|
|
|
{
|
|
|
"title": "Nest eggs",
|
|
|
"body": "Making your money work...",
|
|
|
"tags": [ "cash", "shares" ],
|
|
|
"comments": [
|
|
|
{
|
|
|
"name": "John Smith",
|
|
|
"comment": "Great article",
|
|
|
"age": 28,
|
|
|
"stars": 4,
|
|
|
"date": "2014-09-01"
|
|
|
},
|
|
|
{
|
|
|
"name": "Alice White",
|
|
|
"comment": "More like this please",
|
|
|
"age": 31,
|
|
|
"stars": 5,
|
|
|
"date": "2014-10-22"
|
|
|
}
|
|
|
]
|
|
|
}
|
|
|
```
|
|
|
|
|
|
我们想要搜索到评论者是Alice,且年龄是28岁的评论,搜索语句如下:
|
|
|
|
|
|
```
|
|
|
GET /_search
|
|
|
{
|
|
|
"query": {
|
|
|
"bool": {
|
|
|
"must": [
|
|
|
{ "match": { "name": "Alice" }},
|
|
|
{ "match": { "age": 28 }}
|
|
|
]
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
```
|
|
|
|
|
|
搜索结果却能够搜索到记录。这是不符合预期的。
|
|
|
|
|
|
这是因为对象数组中JSON 格式的文档被处理成如下的扁平式键值对的结构,comments对象中字段失去关联:
|
|
|
|
|
|
```
|
|
|
{
|
|
|
"title": [ eggs, nest ],
|
|
|
"body": [ making, money, work, your ],
|
|
|
"tags": [ cash, shares ],
|
|
|
"comments.name": [ alice, john, smith, white ],
|
|
|
"comments.comment": [ article, great, like, more, please, this ],
|
|
|
"comments.age": [ 28, 31 ],
|
|
|
"comments.stars": [ 4, 5 ],
|
|
|
"comments.date": [ 2014-09-01, 2014-10-22 ]
|
|
|
}
|
|
|
```
|
|
|
|
|
|
这时候我们可以使用nested object,来保证子对象关系未打散:
|
|
|
|
|
|
```
|
|
|
{
|
|
|
"comments.name": [ john, smith ],
|
|
|
"comments.comment": [ article, great ],
|
|
|
"comments.age": [ 28 ],
|
|
|
"comments.stars": [ 4 ],
|
|
|
"comments.date": [ 2014-09-01 ]
|
|
|
}
|
|
|
{
|
|
|
"comments.name": [ alice, white ],
|
|
|
"comments.comment": [ like, more, please, this ],
|
|
|
"comments.age": [ 31 ],
|
|
|
"comments.stars": [ 5 ],
|
|
|
"comments.date": [ 2014-10-22 ]
|
|
|
}
|
|
|
{
|
|
|
"title": [ eggs, nest ],
|
|
|
"body": [ making, money, work, your ],
|
|
|
"tags": [ cash, shares ]
|
|
|
}
|
|
|
|
|
|
|
|
|
PUT /my_index
|
|
|
{
|
|
|
"mappings": {
|
|
|
"blogpost": {
|
|
|
"properties": {
|
|
|
"comments": {
|
|
|
"type": "nested",
|
|
|
"properties": {
|
|
|
"name": { "type": "string" },
|
|
|
"comment": { "type": "string" },
|
|
|
"age": { "type": "short" },
|
|
|
"stars": { "type": "short" },
|
|
|
"date": { "type": "date" }
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
```
|
|
|
|
|
|
|
|
|
### 父子文档
|
|
|
|
|
|
在 nested objects 文档中,所有对象都是在同一个文档中,而在父-子关系文档中,父对象和子对象都是完全独立的文档。
|
|
|
|
|
|
父-子关系的主要优势有:
|
|
|
|
|
|
- 更新父文档时,不会重新索引子文档。
|
|
|
- 创建,修改或删除子文档时,不会影响父文档或其他子文档。这一点在这种场景下尤其有用:子文档数量较多,并且子文档创建和修改的频率高时。
|
|
|
- 子文档可以作为搜索结果独立返回。
|
|
|
|
|
|
## ES索引生命周期管理是怎么回事?
|
|
|
|
|
|
ES索引生命周期管理分为4个阶段:hot、warm、cold、delete,其中hot主要负责对索引进行rollover操作,warm、cold、delete分别对rollover后的数据进一步处理。
|
|
|
|
|
|
|
|
|
phases | desc
|
|
|
--- | ---
|
|
|
hot | 索引更新和查询很活跃
|
|
|
warm | 索引不再更新,但仍然有查询
|
|
|
cold | 索引不再更新,只有很少的查询,而且查询速度也很慢
|
|
|
delete | 索引不需要了,可以安全的删除
|
|
|
|
|
|
|
|
|
### 操作
|
|
|
|
|
|
#### timing
|
|
|
|
|
|
ILM各个阶段的action几乎都需要用到定时器,例如下面这个操作:
|
|
|
|
|
|
```
|
|
|
curl -X PUT "localhost:9200/_ilm/policy/my_policy" -H 'Content-Type: application/json' -d'
|
|
|
{
|
|
|
"policy": {
|
|
|
"phases": {
|
|
|
"warm": {
|
|
|
"min_age": "1d",
|
|
|
"actions": {
|
|
|
"allocate": {
|
|
|
"number_of_replicas": 1
|
|
|
}
|
|
|
}
|
|
|
},
|
|
|
"delete": {
|
|
|
"min_age": "30d",
|
|
|
"actions": {
|
|
|
"delete": {}
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
'
|
|
|
|
|
|
# 应用到模板上
|
|
|
PUT _index_template/my_template
|
|
|
{
|
|
|
"index_patterns": ["test-*"],
|
|
|
"template": {
|
|
|
"settings": {
|
|
|
"number_of_shards": 1,
|
|
|
"number_of_replicas": 1,
|
|
|
"index.lifecycle.name": "my_policy",
|
|
|
"index.lifecycle.rollover_alias": "test-alias"
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
上述warm阶段通过min_age配置了1d,意思是索引从创建至少需要经历1天的时间才会被移入到warm阶段,另一个delete阶段min_age配置了30d,意思是索引在创建后的30天会被删除;通常情况下warm、cold、delete的起始时间是从索引创建开始算起的,但是如果配置了hot,那么后面phrase配置的时间应该大于rollover的时间。
|
|
|
|
|
|
#### Hot Rollover
|
|
|
|
|
|
```
|
|
|
curl -X PUT "localhost:9200/_ilm/policy/datastream_policy" -H 'Content-Type: application/json' -d'
|
|
|
{
|
|
|
"policy": {
|
|
|
"phases": {
|
|
|
"hot": {
|
|
|
"actions": {
|
|
|
"rollover": {
|
|
|
"max_size": "50GB",
|
|
|
"max_age": "30d"
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
'
|
|
|
```
|
|
|
|
|
|
我们定义了一个策略,策略中使用了hot rollover action,当引用该策略的索引满足rollover中任一一个条件时就会触发滚动操作,生成新的索引,新索引的格式是 ^.*-\d+$ (如,index_name-000001)
|
|
|
|
|
|
#### Warm Allocate
|
|
|
|
|
|
allocate action主要有两个操作,1、转移数据到warm节点;2、修改索引副本数。
|
|
|
|
|
|
```
|
|
|
PUT _ilm/policy/my_policy
|
|
|
{
|
|
|
"policy": {
|
|
|
"phases": {
|
|
|
"warm": {
|
|
|
"actions": {
|
|
|
"allocate" : {
|
|
|
"number_of_replicas": 0,
|
|
|
"include" : {
|
|
|
"box_type": "cold,warm"
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
```
|
|
|
|
|
|
其中include配置的标签需要和elasticsearch.yml中配置的标签名一致,allocate支持的参数有:
|
|
|
|
|
|
参数 | 描述
|
|
|
number_of_replicas | 分配后索引保持的分片数
|
|
|
include | 至少满足其中一个标签
|
|
|
exclude | 排除包含这些标签的服务器
|
|
|
require | 需要同时满足所有配置的标签
|
|
|
|
|
|
#### Warm Read-Only
|
|
|
|
|
|
配置索引为只读模式
|
|
|
|
|
|
```
|
|
|
curl -X PUT "localhost:9200/_ilm/policy/my_policy" -H 'Content-Type: application/json' -d'
|
|
|
{
|
|
|
"policy": {
|
|
|
"phases": {
|
|
|
"warm": {
|
|
|
"actions": {
|
|
|
"readonly" : { }
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
'
|
|
|
```
|
|
|
|
|
|
#### Warm Force-Merge
|
|
|
|
|
|
指定索引合并后保留的segment数,过多的 segment 对查询性能有影响,为了充分合并数据,建议设置为 max_num_segments = 1
|
|
|
|
|
|
```
|
|
|
curl -X PUT "localhost:9200/_ilm/policy/my_policy" -H 'Content-Type: application/json' -d'
|
|
|
{
|
|
|
"policy": {
|
|
|
"phases": {
|
|
|
"warm": {
|
|
|
"actions": {
|
|
|
"forcemerge" : {
|
|
|
"max_num_segments": 1
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
'
|
|
|
```
|
|
|
|
|
|
需要注意的是,设置forcemerge action后索引会被修改为只读模式
|
|
|
|
|
|
#### Warm Shrink
|
|
|
|
|
|
通过shrink action可以降低索引的分片数量,同样执行该action操作后,索引会被修改为只读模式,同时索引名也会发生变化,如原来索引名称是“logs”,执行后的名称会多一个shrink-前缀,即“shrink-logs”。
|
|
|
|
|
|
```
|
|
|
curl -X PUT "localhost:9200/_ilm/policy/my_policy" -H 'Content-Type: application/json' -d'
|
|
|
{
|
|
|
"policy": {
|
|
|
"phases": {
|
|
|
"warm": {
|
|
|
"actions": {
|
|
|
"shrink" : {
|
|
|
"number_of_shards": 1
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
'
|
|
|
```
|
|
|
|
|
|
#### Cold Freeze
|
|
|
|
|
|
冻结索引意思就是关闭索引。
|
|
|
|
|
|
```
|
|
|
PUT _ilm/policy/my_policy
|
|
|
{
|
|
|
"policy": {
|
|
|
"phases": {
|
|
|
"cold": {
|
|
|
"actions": {
|
|
|
"freeze" : { }
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
``` |